Компьютерная лингвистика и анализ текста
Компьютерный анализ текста на естественном языке активно развивается. К сожалению, внедрение математических методов в обработку текста происходит в то время, когда лингвистическая составляющая алгоритмов представлена явно недостаточно.
Александр Ермаков,
ведущий разработчик фирмы «Гарант-Парк-Интернет», ermakov@metric.ru
Компьютерный анализ текста на естественном языке активно развивается в последние годы многими коллективами. Доступные сегодня вычислительные мощности позволяют применять для обработки больших массивов документов широкий класс математических методов, способствующих эффективному решению задач поиска, классификации, кластерного анализа, выявления скрытых закономерностей в данных и др. С иллюстрацией подобных приложений можно познакомиться, к примеру, на сайте http://research.metric.ru.
К сожалению, внедрение математических методов в обработку текста происходит в то время, когда собственно лингвистическая составляющая алгоритмов представлена явно недостаточно, и это не позволяет достичь высокого качества работы прикладных систем. Устойчивый уклон в область статистических методов анализа привел к тому, что компьютерная лингвистика оказалась невостребованной. В самом деле, во всех известных русскоязычных системах подобного класса из лингвистического обеспечения используется лишь морфологический словарь, позволяющий отождествлять различные словоформы, тогда как алгоритмы синтаксического анализа реализованы исключительно в автоматических переводчиках и вызывают множество нареканий в связи с невысокой точностью.
Поговорим о проблемах компьютерной лингвистики, касающихся прежде всего грамматического разбора текста на естественном языке. При этом оставим за рамками статьи специфические вопросы, связанные с машинным переводом, и, опираясь на личный опыт разработки информационно-поисковых систем (ИПС) в компании «Гарант-Парк-Интернет», рассмотрим перспективы применения лингвистики в контексте таких систем. Создание качественного синтаксического анализатора позволяет надеяться на эффективное решение задачи поиска в информации на естественном языке.
Сложность практической реализации приемлемого анализатора текста обусловлена наличием тесной связи между синтаксисом и надъязыковой семантикой. Так, в синтаксически эквивалентных фразах «человек стрелял из ружья» и «человек стрелял из окна» «ружье» представляет аргумент глагола-предиката «стрелять» в роли косвенного дополнения, а объект «окно» — обстоятельство места, являющееся дополнительной характеристикой всей ситуации в целом. Для решения подобных проблем (называемых синтаксической омонимией) необходимо создание специального толково-комбинаторного словаря, включающего в себя синтаксическую и семантическую информацию о сочетаемости слов. При этом он, с одной стороны, должен декларировать, что аргумент предиката «стрелять», представляющий орудие действия, относится к классу «оружие», а с другой — установить все слова, относимые к этому классу: «ружье», «рогатка» и др.
Формально целью синтаксического разбора является построение дерева зависимостей между словами во фразе. В случае удачи предложение сворачивается в полносвязное дерево с единственной корневой вершиной. Поскольку одна словоформа может соответствовать нескольким грамматическим формам слова, в том числе для различных слов (например, «стали» у существительного «сталь» и глагола «стать»), в ходе анализа необходимо производить свертку предложения для всех возможных вариантов. Те же из них, которые приводят к максимальной свертке фразы (с минимальным числом висячих вершин), предлагается считать наиболее достоверными при разборе предложения.
Порядок применения правил разбора управляется его алгоритмом, который на каждом шаге проверяет возможность применения следующего правила к очередному фрагменту фразы (двум-трем словам, знакам препинания и т. п.). В случае удачи фрагмент сворачивается. Обычно это приводит к его замене одним главным словом, т. е. удалением подчиненных слов. После чего разбор продолжается. Если дальнейшее применение правил невозможно, на любом из шагов совершается откат. При этом последний свернутый фрагмент восстанавливается, и предпринимается попытка применить другие правила. Окончательным вариантом разбора следует считать такую последовательность применения правил, которая приводит к максимальной свертке предложения.
Так, в ходе разбора фразы «усталые гуси и утки стали снижаться», возникают следующие варианты:
(усталые -> гуси + утки ) ~> (стали <- снижаться ),
(усталые -> гуси ) и (утки ~> стали <- снижаться),
((усталые -> гуси ) + (утки <- стали)) снижаться
и ряд других.
Здесь каждая пара скобок включает слова, обработанные по некоторому правилу на очередном шаге анализа. Прямая стрелка указывает на отношение подчинения при свертке именных и глагольных групп, знак «плюс» — на свертку равноправных однородных членов, а волнистая стрелка — на связь подлежащего со сказуемым. Такое представление соответствует дереву зависимостей во фразе.
Очевидно, что только первый вариант относится к полному разбору — полносвязному дереву с одной вершиной, представленной глагольной группой «стали снижаться». Второй вариант неполон, но все установленные синтаксические связи являются правильными. Третий вариант говорит об ошибке, вызванной наличием у существительного «сталь» формы «стали» в родительном падеже множественного числа, и выделена именная группа «утки стали» по аналогии с «полосы стали», «ковка стали».
Так как процессу разбора соответствует целое дерево вариантов свертки фразы, то производительность алгоритма падает экспоненциально с ростом числа используемых правил и количества слов в предложении. Сложные предложения могут порождать тысячи вариантов разбора, ввиду чего на практике приходится ограничивать допустимое число рассматриваемых вариантов.
Наиболее просто решается проблема выделения в тексте именных групп — устойчивых словосочетаний, состоящих из существительных и связанных с ними прилагательных, например «развитие сельского хозяйства». Такие группы характеризуют содержание текста и служат для тематического индексирования, автоматической рубрикации, уточнения запроса при поиске и т. п.
Синтаксические отношения в пределах именных групп могут быть описаны десятком правил контекстно-независимой грамматики, учитывающих лишь согласование грамматических форм. Например, если прилагательное относится к следующему за ним существительному, то они должны быть согласованы между собой по падежу и числу, а в единственном числе еще и по роду.
В ходе полного синтаксического разбора фразы возможно установление синтаксических ролей именных групп в предложении. Это позволяет ранжировать их по степени значимости для автора, что соответствует пониманию ключевых идей текста. Наиболее важными являются слова из группы подлежащего, затем сказуемого, прямого дополнения, косвенного дополнения, обстоятельства — таковы особенности русского языка.
Ниже приведен пример разбора (как видно, пока не полного) нашим анализатором фразы:
(клинки, <- изготовленные) (великими -> (мастерами <- древности)), становились
(символами <- (гордости и+ ( чести <- ((живущих и + будущих) -> (поколений <- японцев)))))
После выбора наилучшего варианта разбора включается алгоритм анализа дерева зависимостей, который собирает все именные группы и разворачивает однородные члены. Вместе с тем входящие в них слова ставятся в согласованные грамматические формы.
Полный список выделенных именных групп, исключая состоящие из одного слова, следующий:
великий мастер древности, великий мастер, мастер древности, символ чести сегодняшнего поколения японца, символ чести сегодняшнего поколения, символ чести вчерашнего поколения японца, символ чести вчерашнего поколения, символ чести, символ гордости, честь сегодняшнего поколения японца, честь вчерашнего поколения японца, честь сегодняшнего поколения, честь вчерашнего поколения, сегодняшнее поколение японца, вчерашнее поколение японца, сегодняшнее поколение, вчерашнее поколение, поколение японца.
Заметим, что последняя часть разобранной фразы допускает второй, столь же полный вариант разбора:
(символами <- ( (гордости и + чести) <- ( (живущих и + будущих) -> (поколений <- японцев) ) ) ),
порождающий дополнительные именные группы:
гордость будущего поколения японца, гордость живущего поколения японца, символ гордости будущего поколения японца, символ гордости живущего поколения японца.
Наличие нескольких равноправных вариантов разбора есть явление синтаксической омонимии, разрешение которой невозможно без привлечения семантики, а иногда и прагматики, как в данном случае.
Смысловая связь между понятиями предложения в общем случае может быть описана глаголом-предикатом, аргументами которого выступают данные понятия. Установление таких синтактико-семантических связей позволяет сформировать логическую схему ситуации, описываемой во фразе.
Однако для этого требуется словарь моделей управления глаголов. В таком словаре для всех глаголов (около 20 тыс. в русском языке) должно быть указано, какими падежами и с какими предлогами производится это управление. Для каждой модели следует обозначить семантические роли аргументов глагола, что позволит дифференцировать связи по смыслу, выявляя, например, орудие действия, цель, место и т. п. Вообще в лингвистике выделяют около 30 подобных семантических ролей.
Как уже отмечалось, присутствие омонимии в тексте требует привлечения семантической информации для качественного синтаксического разбора, которая может быть добавлена к модели управления в форме ограничений на допустимые значения каждого аргумента глагола. Так, если известно, что у глагола «подписывать» первый аргумент (подлежащее) может быть только одушевленным, а второй, в роли прямого дополнения, — неодушевленным, то это позволит разрешить омонимию во многих случаях.
В результате анализа простое предложение текста преобразуется в строку таблицы реляционной базы данных. При этом имя таблицы соответствует предикату-глаголу, а столбцы — семантическим ролям участников ситуации, описываемой этим глаголом. По окончании анализа пары предложений в таблице с именем «арендовать» могут появиться следующие записи:

Такое представление позволяет решать задачу фактографического поиска, например: «найти всех персон, контактировавших с организацией X определенным образом». То есть выявить все одушевленные именные группы, связанные с X посредством заданных глаголов в соответствующей синтаксической роли.
Связи, возникающие между строками таблиц при совпадении значений полей, порождают семантическую сеть на множестве целевой коллекции анализируемых документов. Причем связи эти дифференцированы по типам, что позволяет искать ответы на сложные вопросы следующего вида: «Найти всех арендодателей в Москве, у которых арендаторы торгуют маслом». Соответствующий запрос к базе данных на языке SQL будет выглядеть так:
SELECT Агенс FROM Арендовать WHERE Обстоятельство = «Москва» AND Бенефактив IN (SELECT Агенс FROM Торговать WHERE Пациенс = «масло»)
Аналогичным образом вопрос на естественном языке может быть преобразован в стандартный запрос к базе данных на SQL. При этом глагол определяет имя таблицы, в которой ведется поиск, заданные в вопросе аргументы глагола представляют поисковые ограничения на значения полей в таблице, а вопросительное слово («что, где, сколько») указывает, в каком столбце вести поиск.
Вершиной компьютерного анализа текста является автоматическое реферирование. Наличие семантической сети понятий, соединенных глаголами, позволяет сформулировать основные идеи текста документа, отраженные в часто встречающихся понятиях и связях, в виде простых предложений, например:
Клинки изготавливаются японскими мастерами. Запрещен вывоз старинных клинков. Технология производства известна. Русские мастера воспроизводят клинки. Клинки продаются.
Словарь моделей управления и семантической сети с дифференцированными связями значительно облегчает подобный синтез. Отдельной проблемой является выбор оптимального порядка фраз. Возможно, при этом будет полезно знание коммуникативной структуры текста — иерархии тем и рем, которая отражает логику изложения автором материала.
Задача тема-рематического анализа решается в ходе синтаксического разбора фразы: понятия из группы подлежащего представляют темы; понятия-дополнения глагола — ремы, которые могут стать темами последующих фраз; обстоятельства — лишь некий фон, на котором развертываются описываемые события.
Общая схема подобного анализа текста приведена на рисунке.
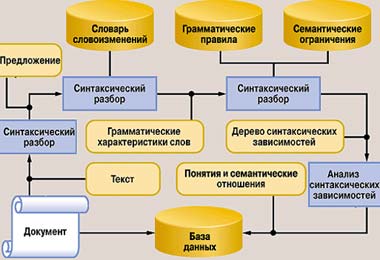
Общая схема синтаксического анализа текста в информационно-поисковой системе
В заключение отметим, что, несмотря на ограниченность синтаксических анализаторов, работающих пока без привлечения семантики, их применение уже сейчас открывает качественно новые возможности для систем компьютерного анализа текста. Это, в частности, подтверждают и наши разработки. Синтаксический анализатор русского языка, реализующий выделение именных групп и снятие омонимии, уже внедряется в очередную версию поисковой системы Russian Context Optimizer для СУБД Oracle. С демонстрацией анализатора можно познакомиться на странице http://research.metric.ru/syntdemo/syntdemo.asp.
![]()
Источник: Мир ПК, №09/2002



Комментарии 1
Вот интересная тема, но в конце - без привлечения семантики. Многое ведь уже есть. Можно разметить документ в формате: подлежащее, сказуемое, дополнение. можно связать предложения между собой бинарными связами, выделив семантику по паре подлежащих. Можно создать структуру по словам подлежащих, описав из свойствами. Можно привязать к свойствам функциональные структуры. Вопрос в сложности алгоритма построения дерева решений. Но и его можно построить и провести семантический анализ в дополнение к синтаксическому. Мечта у меня - создать семантический анализатор на основании метаданных.