Концентрируя и анализируя данные о клиентах
Объемы данных, хранимых и обрабатываемых информационными системами предприятий, стремительно возрастают. Растут при этом и объемы тех данных, которые несовместимы между собой из-за несовпадающих форматов, противоречивых значений и т. д. Что делать?
Алексей Резниченко
Объемы данных, хранимых и обрабатываемых информационными системами организаций и предприятий, стремительно возрастают. Но растут при этом и объемы тех данных, которые несовместимы между собой из-за несовпадающих форматов, противоречивых значений, версионности и т. д. Их появление обуславливается главным образом тем, что они приходят из различных внутренних и внешних по отношению к организации источников.
Можно выделить ряд факторов, приводящих к несовместимости данных:
● отсутствие синхронизации между записями об одних и тех же объектах (например, о клиентах), которые находятся в базах данных (файлах) различных информационных систем;
● фрагментация. В каждом приложении используются только те данные, которые нужны этому конкретному приложению, что само по себе не приводит к фрагментации. Но, как правило, БД различных информационных систем хранят только ту информацию, которая используются их приложениями. Поэтому записи об одних и тех же объектах в разных БД содержат различные атрибуты, имеют разную структуру, и если возникает необходимость в более полных сведениях об объекте, то формирование соответствующих консолидированных записей оказывается очень непростой задачей;
● противоречивость данных об одних и тех же объектах, содержащихся в нескольких информационных системах;
● дублирование записей об одном и том же объекте не только в различных ИС (в одной есть клиент «Юлия Андреева», в другой «Юлия Иванова», в третьей «Ю. Иванова», а имеется в виду один и тот же человек), но даже в одной системе. При этом разные значения одного и того же поля появляются и как результат ошибок, и на вполне законном основании …
Пожалуй, наиболее острой проблема несовместимости является для данных о клиентах. Именно эта информация, её качество и полнота критически важна для многих современных предприятий различных отраслей. Ведь, скажем, обострение конкуренции на российском рынке банковских продуктов и услуг прежде всего выражается в борьбе за клиента — массового, розничного, корпоративного или VIP, за его привлечение и удержание. Успех в этой борьбе зависит от многих факторов, и наличие полной и достоверной информации о клиенте и эффективная работа с ней - не последний из них. Но чтобы эту информацию можно было извлечь в любой момент, данные о клиентах из различных систем должны быть интегрированы, то есть собраны, обработаны, проанализированы и подготовлены к дальнейшему использованию в деятельности банка.
Для интеграции данных о клиентах (CDI — Customer Data Integration), в ходе которой решается и проблема их совместимости, чаще всего применяются традиционные технологии создания и ведения хранилищ данных - извлечения (Extract), преобразования (Transfornation), загрузки (Load), - в которых интенсивно используются метаданные: модели исходных и результирующих данных, правила их верификации, преобразования, слияния (из различных источников) и загрузки (последние часто задаются процедурно) и т. д.
Но в последние годы предложены новые технологии, которые можно рассматривать и как расширение традиционных технологий хранилищ. И теперь они выходят на первый план в решении важных практических задач, включая интеграцию данных о клиентах.
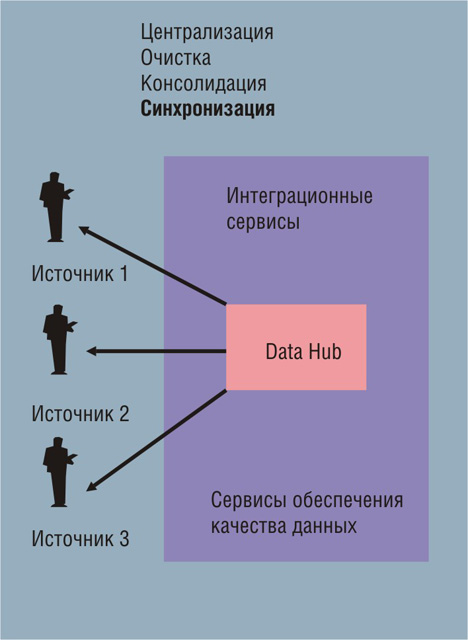
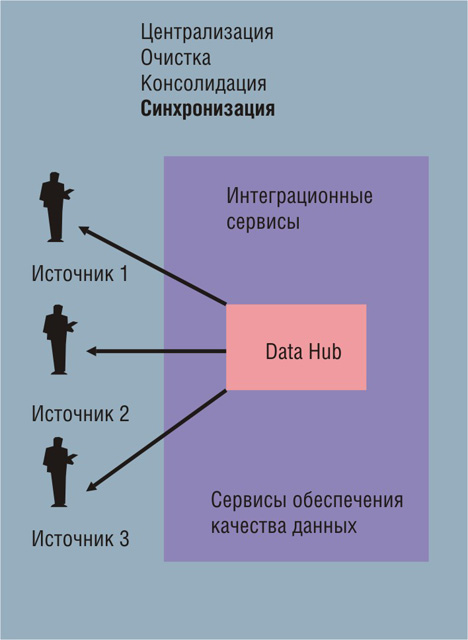
Рис. 1. Обработка данных в технологии MDM на этапе “Синхронизация”
MDM: концепция гармонизации данных
Наиболее полный подход к решению проблем несовместимости данных, их гармонизации предлагает концепция MDM (Master Data Management — управление основными или мастер-данными). В её рамках для описания ключевых объектов предприятия (клиентов, персонала, поставщиков, партнеров, продуктов, услуг и т. д.) предлагается использовать согласованный набор идентификаторов (identifiers); в первом приближении это ключевые поля классификаторов и справочников, которые дополняются различными атрибутами. Фактически такой набор обязательно (хотя, как правило, неосознанно) формируется в информационной системе любой организации, а для использования концепции MDM его нужно явным образом определить, проанализировать и реорганизовать (например, добавить глобальный идентификатор, который однозначно определяет объект для всех информационных систем предприятия). В частности, глобальным идентификатором человека может быть цифровой код, так как фамилия, имя и другие атрибуты для этого не годятся. А когда такой набор создан, можно приступить и к проблеме несовместимости атрибутов.
Концепция MDM стала результатом обобщения технологий, методов и подходов, разработанных практиками прежде всего для решения таких задач, как управление данными о продуктах (PDM — Product Data Management). Нередко термин MDM переводят как управление НСИ (нормативно-справочной информацией), что неверно, так как весь смысл этой концепции сводит к одному, хотя и очень важному, случаю ее применения, оставляя в стороне, к примеру, интеграцию данных о клиентах.
В настоящее время уже сформировался рынок продуктов класса MDM, большинство из которых называется Data Hubs — концентраторы данных.
Способы и стили реализации MDM
Наиболее общая схема обработки данных согласно MDM такова: данные из систем-источников должны быть прежде всего собраны и централизованы (этап «Централизация»). После этого на этапе «Очистка» выполняется их проверка, очищение и консолидация (например, данные из различных систем-источников о клиенте «Денис Игнатов» объединяются в единую «золотую» запись) и помещаются в централизованное хранилище - Data Hub. И, наконец, на этапе «Синхронизация» данные из Data Hub направляются в системы-источники для их актуализации. В результате все данные вовлеченных систем, соответствующие этому объекту, оказываются согласованными и гармонизированными между собой (см. рис. 1).
Чаще всего операции c данными на всех упомянутых этапах выполняются физически - так происходит, например, в тех случаях, когда применяется транзакционный стиль (transaction style) реализации MDM; но есть и другие стили, предусматривающие логическое выполнение операций. Логическим (а не физическим!) может быть и хранилище Data Hub - в этом случае «золотые записи» формируются из источников по запросу на лету, но физически не хранятся. Последнее возможно и при простой синхронизации данных между системами-источниками, одна из которых является главной и в какой-то мере выполняет роль Data Hub. Впрочем, такой подход считается слишком примитивным для настоящих продуктов класса MDM, где используются более сложные способы синхронизации - например, через центральный узел (Hub), содержащий репозиторий правил синхронизации и преобразования данных. Но различные стили и подходы к реализации MDM в конкретных продуктах, как правило, сочетаются (см., например, PC Week/RE, № 39/2004 и исследование Gartner «Vendors Have Different Approaches to Implementing Master Data Management»).
Аналитики Gartner выделяют четыре стиля (или архитектуры) реализации MDM: консолидационный (consolidation); реестровый (registry); основанный на сосуществовании (coexistence); транзакционный (transaction). Выбор между ними надо проводить исходя из наиболее приоритетных задач, для решения которых и необходим MDM (см. исследование Gartner «How to Choose the Right Architectural Style for Master Data Management»), а также из того, кто будет выступать в роли авторов основных данных, несущих ответственность за них. Если эти авторы – владельцы источников, то, возможно, оптимален реестровый стиль, который в простейшем случае сводится к созданию индекса для доступа к соответствующим элементам основных данных в системах-источниках для формирования «золотых записей» по запросу. Если же таковыми являются владельцы центрального хранилища, то скорее всего предпочтителен транзакционный стиль.
Консолидация данных с учетом семантики
При выполнении этапов «Очистка» и «Консолидация» большое значение имеет учет семантики, поэтому концентраторы данных разрабатываются, как правило, для определенной предметной области, например:
● Customer Data Hub (CDH) — концентратор данных о клиентах;
● Product Information Management Data Hubs (PIM DH) — концентратор данныхо продуктах;
● Financial Consolidation Data Hub (FC DH) — концентраторфинансовых данных.
Для учета семантики предметной области в состав концентратора данных включается компонент, который можно определить как специализированный (с учетом особенностей этой предметной области) механизм настройки источников информации (включая справочные БД), методов преобразования данных, правил поиска дубликатов и т. д. Для применения в конкретных проектах выполняется более детальная настройка этого механизма.
Первый и, судя по доступным источникам, пока единственный
проект по консолидации данных о клиентах с применением Data Hub в СНГ был
выполнен в
Как отметил ведущий консультант-разработчик отдела проектирования хранилищ данных компании «Борлас» и архитектор этого проекта Алексей Курбатов, механизм настройки источников информации, методов преобразования, правил поиска и объединения дубликатов, имеющийся в продукте Oracle Customer Data Hub, в этом проекте использовался частично, так как был разработан и предварительно настроен с учетом реалий США, которые отличались от казахстанских. Поскольку в продукте Oracle предусмотрена возможность подключения внешних процедур, участники проекта разработали такие процедуры, учитывающие специфику Казахстана.
Тенденции рынка CDI
Основной сегмент рынка MDM-продуктов составляют
концентратороы данных о клиентах. В
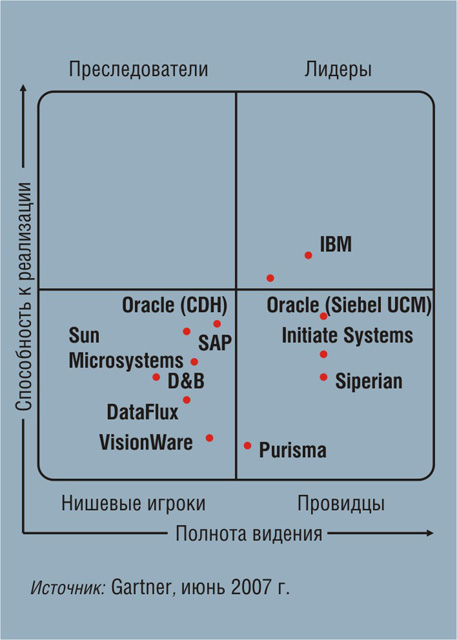
Рис. 2.
“Магический квадрант”
В этом году Gartner опубликовала очередное исследование в
формате «магического квадранта», посвященное концентраторам данных: «Magic
Quadrant for Customer Data Integration Hubs, 2Q07» (см. рис. 2). Авторы
исследования отмечают быстрый рост рынка CDI: в
Однако чтобы консолидированные транзакционные данные в полной мере использовались для оперативного управления предприятием, их нужно проанализировать. Для этого широко используются средства получения регламентной отчетности и OLAP-инструменты. Кроме того, в последние годы нарастает применение средств углубленного анализа (advanced analytics) на основе методов статистики, прикладной математики и искусственного интеллекта, относимых к Data Mining: деревья классификации и регрессии (classification and regression trees), также известные как деревья решений; нейронные сети (neural networks); алгоритмы поиска ближайших k-соседей (k-nearest-neighbors technique of memory-based reasoning); кластеризация (clustering) и др.
Продукты класса Data Mining разрабатывают и компании-специалисты, в том числе известная в мире российская «Мегапьютер Интеллидженс», и крупные поставщики - Oracle, Microsoft, IBM и т. д. Современные приложения этого класса достаточно дружественны, а некоторые методы вполне доступны для самостоятельной работы с ними аналитиков и «продвинутых» бизнес-пользователей.
Эти продукты широко применяются для анализа данных о клиентах. Однако среди них выделяется подкласс решений, наиболее предпочтительных для анализа данных о клиентах в рамках CRM, — управления отношениями с клиентами. Основная их особенность заключается в том, что они должны поддерживать быстрое принятие решений в процессе взаимодействия с клиентами, которых может быть очень много. В других случаях эти продукты должны автоматически создавать тысячи моделей, например если необходимо определять целевые группы клиентов при продаже тысяч наименований товаров в розничной торговле.
В этом году Gartner по традиции опубликовала «магический квадрант» по продуктам класса Data Mining (см. рис. 3). Аналитики из этой компании отмечают, что продукты класса Data Mining для анализа данных о клиентах предлагают фирмы SAS, SPSS («лидеры» исследования) и Angoss, специализирующиеся в данной области, а у поставщиков бизнес-приложений вроде Microsoft и SAP их еще нет - очевидно, вследствие того, что они уделяют основное внимание операционному CRM (продажи и обслуживание). Кроме того, их клиенты — это в основном компании, которые практикуют CRM в рамках взаимодействия «бизнес - бизнес» (B2B), тогда как анализ данных о клиентах наиболее востребован при взаимодействии «бизнес - клиенты» (B2C).
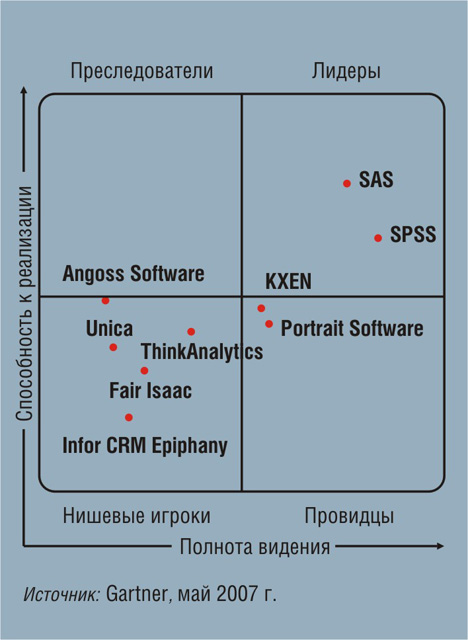
Рис. 3.“Магический квадрант” по средствам класса Data Mining для анализа данных о клиентах
Итак, в настоящее время рынок предлагает широкий спектр альтернативных софтверных продуктов для консолидации и анализа данных о клиентах. Можно использовать системы, реализующие традиционные технологии хранилищ данных (ETL), разнообразные аналитические инструменты для получения регламентированной отчетности, OLAP-анализа и углубленного анализа (Data Mining). Получают признание и Data Hubs, но в целом в использовании продуктов класса MDM идёт переход от применения в отдельных важных задачах, таких как консолидация и анализ данных о клиентах или управление НСИ, к более широкому подходу, когда гармонизируются данные не отдельных задач, а подсистем или информационной системы организации в целом.
Источник: PC Week
Похожие статьи

ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 2
Интересно, а в Одноклассниках "справочники" чистить будут? А то даже города люди умудряются пятью способами написать. Или подождут лет 10 до полного замусоривания, а потом и смысла не будет. :)
К ECM системы интеграции, добычи и анализа данных имеют весьма отдаленное значение. Если только все функции систем класса CDI, MDM, DM войдут в состав BPM, который как раз и входит в состав ECM. Вот тогда можно создавать крутые БП добычи и анализа данных. Все реально, нужно только разработать функциональные сервисы по SOA, и вперед...