Big Data и Big Content – навязанная необходимость или реальная потребность?
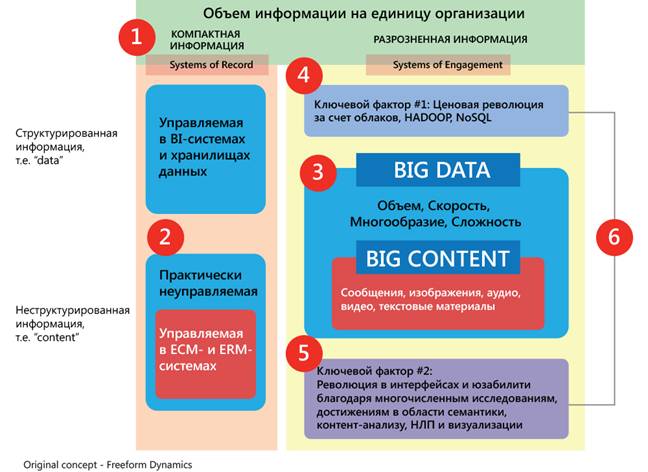
Последние лет десять компании накапливают свои данные в том, что мы называем учетной системой. В будущем, чтобы оставаться на плаву, компаниям придется иметь дело с системами обеспечения взаимодействия и вовлечения.
Благодаря бесконечной веренице статей о Big Data («большие данные» или данные большого объема), задумываешься над вопросом соотношения структурированной и неструктурированной информации. Некоторая часть этих размышлений, довольно патогенных, наводит на мысль: «Так, если каждый собирается говорить о Big Data, то мне тоже нужно». Суровая реальность такова, что неструктурированные данные – «нелюбимый ребенок» инструментов Big Data, – причина, по которой невозможно использовать столь ценную информацию в полной мере. Между тем, наше сообщество (пользователи, разработчики решений и консультанты) неплохо осведомлено о том, насколько неоднозначен этот вопрос о неструктурированной информации.
|
Systems of Engagement - системы социального взаимодействия, строятся в первую очередь для сотрудников, чтобы обеспечить оптимизацию накопления, передачи, поиска и анализа неструктурированной информации. Направление включает в себя: социальные платформы и приложения (для поддержки и расширения сотрудничества); интеграцию разрозненных систем, которые должны работать как единое целое (управление бизнес-процессами, управление цепочками поставок, управление персоналом). |
Вице-президент IBM Ючун Ли так описал свое видение связи между учетной системой (System of Record) и системой взаимодействия (Systems of Engagement):
Последние лет десять компании накапливают свои данные в том, что мы называем учетной системой. В будущем, чтобы оставаться на плаву, компаниям придется иметь дело с системами обеспечения взаимодействия. А начнется все с оценки того, как наладить взаимодействие с клиентом, используя все доступные каналы. Благо существуют средства для проведения анализа и статистика. С точки зрения технической реализации, мы считаем, что будущее в обработке большого объема данных лежит за привлечением возможностей облаков. Своевременный анализ, функциональная платформа и правильная архитектура позволят получить максимальную отдачу от накопленных данных.
Итак, я попытался представить свое видение связей между Big Content и Big Data на одном изображении.
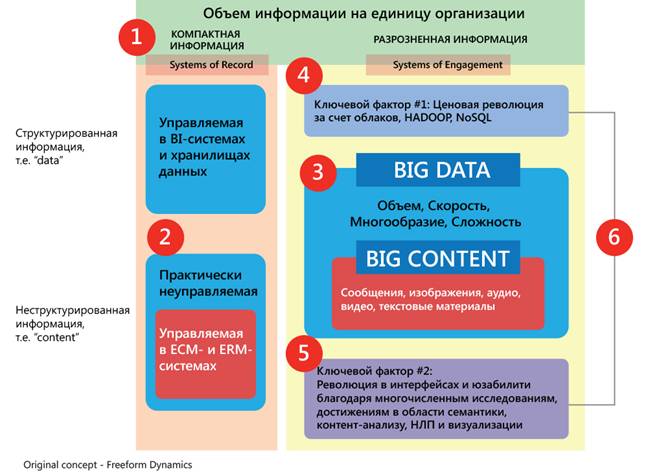
Идем по диаграмме согласно цифрам. Обо всем по порядку:
1. Последние десятилетия мы стремились к тому, чтобы привести информацию к высоко структурированному виду, так мы можем использовать ее максимально эффективно. Архитектура учетных систем и систем взаимодействия предусматривает пока лишь работу по распознаванию, хранению, обмену информацией в рамках бизнес-процессов.
2. Мы проделали хорошую работу и научились неплохо управлять структурированной информацией, но не нашли подхода к неструктурированной информации. И это не только потому, что в процентном соотношении неструктурированной информации больше (организации обычно сетуют на то, что 80% информации не пригодны для управления), но и потому, что инструменты для работы с неструктурированной информацией, просто-напросто, отсутствовали.
3. Системы взаимодействия генерируют огромные объемы новой информации как структурированной, так и неструктурированной. Существуют предпосылки того, что к 2020 году, количество устройств возрастет с 400 миллионов до 50 миллиардов, и все они будут связаны между собой посредством Интернет. К 2020 году хранить объемы информации, с которым справляются пока лишь суперкомпьютеры вроде IBM Watson, мы сможем в своих смартфонах, более того, будем иметь постоянный доступ к ней. Разница между «несодержательной» и «содержательной» информацией в учетной системе в том, что последняя содержательна сама по себе и в совокупности. Другими словами, мы можем без труда распознать некоторые значения или часть данных, которые относятся к конкретной транзакции или процессу. Гораздо сложнее, да и дороже, то же самое проделать с «обломками» информации, которые имеют значение, лишь собравшись воедино.
4. Применение облачных технологий, таких как Hadoop и NoSQL, позволяет снизить стоимость проведения анализа больших объемов информации
5. Благодаря многочисленным исследованиям, достижениям в области семантики, контент-анализу мы можем сегодня оперировать большими объемами информации, в том числе, и мало структурированными. Кроме того, обработка данных на естественном языке и визуализация технологий ведут нас к тому, что анализом данных будут заниматься не технические специалисты, а руководящий или административный аппарат.
6. И наконец, сочетание облачных технологий – как это отражено в цитате представителя IBM – новая существующая возможность, которая позволяет оперировать большими массивами информации. Фактически, это новый инструмент для мгновенной оценки и структурирования данных. Применение облачных технологий направлено не только на получение материальной выгоды, но и позволит раскрыть истинную ценность информации, спрятанную на цифровой «свалке».
Перевод: Артемьева Екатерина.
Похожие статьи


Комментарии 0