Как объять необъятное?
Как объять необъятный информационный океан? Читайте здесь.
По-моему, задача в принципе не выполнимая. Даже если считать, что необъятное знание состоит из конечного множества областей знаний, группирующих в себе знания в определенной области, объем знаний в каждой из этих областей постепенно стремится к бесконечности. Как не потеряться в таком объеме? Имхо, лучшее, что придумано на сей день в этом направлении - это формирование так называемых «сводов знаний» (body of knowledge или BoK). Эти своды разрабатываются различными организациями, ассоциациями, институтами для разных областей. Но содержат они не столько всеобъемлющие знания о той или иной области, сколько основные аспекты, имеющие долговременную теоретическую и практическую ценность. По сути, такие своды задают ключевые направления в рамках областей знаний, а выбирать нужное направление и искать нужную информацию предстоит уже нам - простым смертным :), исходя из наших текущих практических интересов.
Примеры сводов знаний:
● SWEBOK (Software Engeneering Body of Knowledge), разработка IEEE
● PMBOK (Project Management Body of Knowledge), разработка PMI (Project Management Institute)
● BABOK (Business Analisys Body of Knowledge), разработка IIBA (International Institute of Business Analysis Deploy )
● …
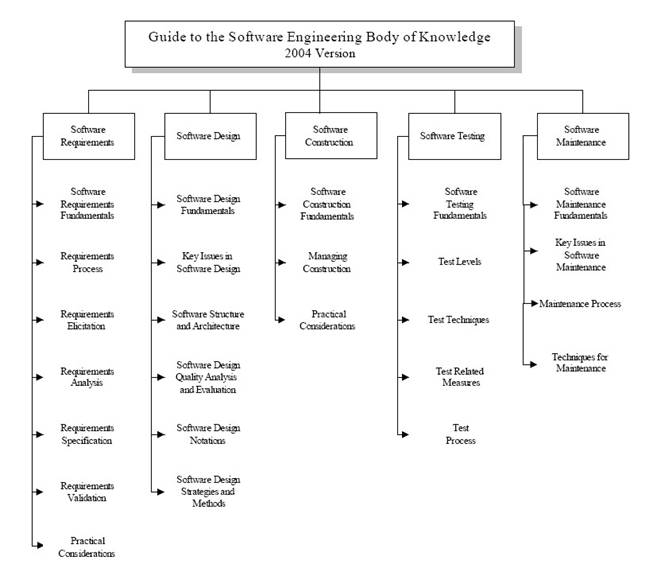
Дерево знаний по SWEBOK (вернее его часть и только верхнего уровня, привожу для иллюстрации, полный текст SWEBOK можно посмотреть здесь):
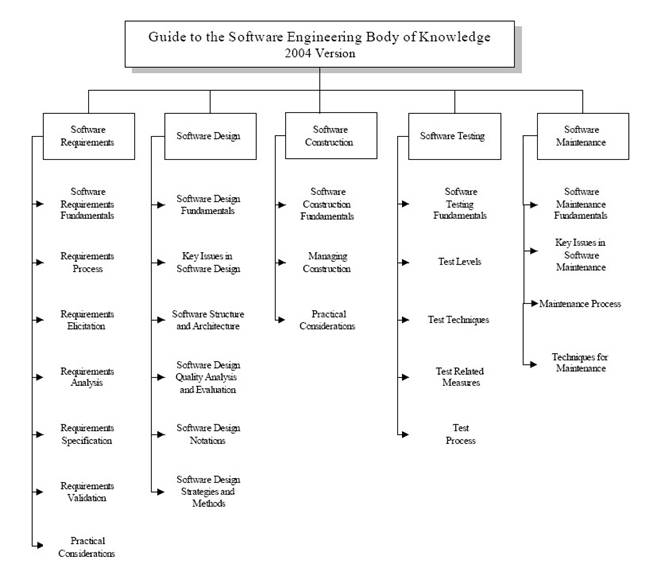
Конечно, эти своды - не догма, многие классификации спорны или не полны (время идет, индустрия развивается), но все же эти своды дают хоть какие-то ориентиры в информационном океане.
Похожие статьи

ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 6
Думаю, свод знаний, как и любой классификатор, имеет две слабые стороны:
1) часто возникает проблема: "В какой раздел следует поместить тот или иной материал?"
2) еще чаще возникает вопрос: "В каком разделе находится то, что мне нужно?"
Полагаю, что поэтому столь быстро растет рынок корпоративных поисковых систем, объединяющих собственно поисковые движки и средства BI. На территорию, где еще недавно фаворитами считались Autonomy и Convera, вторглись не только молодые, да ранние игроки типа Exalead, но и монстры типа IBM, Google и Microsoft со своими продуктами IBM OmniFind, Google's Search Appliance и Microsoft Search Server. Данные продукты используют элементы лингвистического анализа и позволяют организовать поиск информации на естественном языке.
Классификация фунукционалных границ разработки софта может быть различной. Важно, на какую модель функционирования классификация опирается. Полученнные знаний нужно куда-то положить и как-то обработать.
В настоящее врмя используется модель комитета UML. Комитет остановился на достижении, которое назвал - metadata. А дальше не пошел. Понятие metametadata он обошел стороной, назвав его языком описания метаданных.
Развитие управления содержанием кроется именно в разработке технологий работы с метаметаданными.
Наталья, читайте материалы иностранных проектов.
Все мета, мета и так еще два раза разработаны.
2 Александр: Спасибо за совет! Уже три года читаю по утрам, - и пока ничего подобного не видела (не считая пяти-шести не очень убедительных стандартов на метаданные). Ссылочками не поделитесь? :)
Cсылка на спецификацию MOF, в котором описана четырехуровневая метамодель: http://www.omg.org/cgi-bin/apps/doc?formal/02-04-03.pdf