
Релевантность полнотекстового поиска: подход на основе построения терминологической базы документов

В основе предлагаемого подхода лежат две базовые идеи: использование возможностей SQL-запросов к реляционным базам данных при осуществлении поиска; любой текст можно описать посредством предметного указателя.
С. Моисеенко, А.Майстренко
В основе предлагаемого подхода лежат две базовые идеи:
● Использование возможностей SQL-запросов к реляционным базам данных при осуществлении поиска.
● Любой текст можно описать посредством предметного указателя (мы избегаем здесь использовать английский аналог предметного указателя - index, чтобы это не вызывало аналогии со структурами хранения информации во внешней памяти).
Первый пункт предполагает, что необходимая для поиска информация о документе должна содержаться в базе данных. Это даст возможность использовать средства СУБД, связанные с индексированием таблиц и оптимизацией запросов, что в идеале должно обеспечить оптимальную скорость выполнения последних.
Второй пункт связан с вопросом о том, что следует хранить в базе данных, а точнее, в полях таблицы базы данных. Современные серверы БД практически не ограничивают объемы информации, которую можно записать в поле таблицы базы данных. Так, например, IBM DB2 Universal DataBase позволяет хранить неструктурированные текстовые документы объемом до 2 Гбайт [1]. Однако такими возможностями обладают далеко не все СУБД. Кроме того, для эффективного поиска в таких полях, так или иначе, необходимы некоторые вспомогательные структуры хранения данных, построение которых берет на себя СУБД. Эти структуры могут находиться как в базе данных, так и в файловой системе.
Мы исходим из того, что хранить документы в базе данных - излишняя роскошь. Достаточно хранить только ссылки (URL) на документы. Здесь, конечно, могут возникнуть непринципиальные в рассматриваемом контексте проблемы, связанные с изменением местоположения документов. Мы также считаем неэффективным сохранение в базе данных всего словарного множества документа, предлагаемого в работе [2], отдавая должное простоте реализации и быстродействию алгоритма индексирования.
Здесь дело не только в том, что в базу данных попадут одинаковые слова, имеющие разные падежные окончания и т.п. Причем проблему «избыточности» нельзя решить с помощью уникального индекса. Помимо этого такая база данных будет содержать много излишней информации. Это глаголы, служебные слова, местоимения и т.д. В качестве подтверждения сказанного рассмотрим предметный указатель, эффективно используемый для поиска в научно-технической литературе. Предметный указатель это, по сути дела, терминологическая база данного текста. Она включает базовые термины (существительные) и уточненные термины (существительные с определяющими их прилагательными и, возможно, предлогами).
В данной статье предложен алгоритм создания поисковой базы данных документов, построенной по принципу формирования предметного указателя и содержащей как базовые термины, так и их уточнения.
Сама структура такой поисковой словарной базы должна обеспечить не только быстрый, но и релевантный поиск. Релевантность обусловлена еще и тем, что при формировании терминологической словарной базы конкретного документа сохраняется не только сам термин, но и частота его вхождения в документ. Поэтому при выполнении поиска, можно упорядочить его результаты по частоте вхождения искомого термина в документ. Кроме того, можно ввести некоторое пороговое значение f (например, f > 1), которое должно использоваться в качестве критерия отбора записей в поисковом запросе. Причем на это не потребуется дополнительных затрат времени. Основные временные затраты придутся не на поиск, а на предобработку документа (формирование предметного указателя), которая осуществляется не в реальном времени выполнения запроса, а один раз при регистрации документа в системе.
Чтобы сформировать терминологическую базу данных, требуется решить следующие задачи:
● Определить часть речи слова в документе (морфологический анализ).
● Выяснить, что является составным термином (синтаксический анализ). Предполагается, что простым термином является существительное. С составным же термином дело обстоит сложнее, поскольку нужен достоверный критерий того, какая последовательность слов является терминологически связанной.
● Как хранить термин, чтобы слова с разными падежными и т.д. окончаниями записывались в базу данных один раз. Заметим, что эта же проблема должна решаться и при поиске. Например, запрос на поиск слова «программа» должен учесть также и слова: «программе», «программы», «программах» и т.д.
Морфологический анализ можно реализовать, оценивая окончания слов в документе [3]. Для неоднозначно трактуемых слов можно использовать специальную таблицу в БД с атрибутами слово и часть речи, и при анализе просматривать сначала ее, а затем (если слова там нет) выполнять оценку по окончанию слова. В этой же таблице будут находиться и незначительное число слов, принадлежащих неизменяемым частям речи, таким как междометие, наречие и т.п.
При выявлении составных терминов мы исходим из следующих предположений:
● термин должен находиться между знаками препинания;
● в составе термина не должно быть междометий, вводных и служебных слов, союзов и глаголов, которые исключаются на стадии формирования поискового образа документа (см. ниже); возможно расширение списка слов-разделитетей;
● составной термин должен включать существительное;
● порядок слов составного термина может быть произвольным.
Эти предположения можно реализовать с помощью следующего алгоритма формирования терминологической базы данных.
На первом шаге выполняется создание поискового образа документа (ПОД) [3] из копии исходного. ПОД - это информационное наполнение документа, т.е. в нем уже не содержится междометий, вводных и служебных слов и т.д. (смотри выше). При этом исключаемые слова в ПОД заменяются (если они не находятся в начале или конце предложения) некоторым разделительным символом для дальнейшего выявления многословных терминов. Можно для всех исключаемых слов использовать один и тот же символ (например, запятую), чтобы упростить синтаксический анализ.
На втором шаге анализируются фрагменты текста между разделительными символами. Извлекаются любые последовательности слов, среди которых есть существительное. Именно эти последовательности заносятся в таблицу Term (термин). Одновременно с этим можно формировать таблицу TermInDoc (термин в документе), в которой, помимо идентификатора термина (внешний ключ), в поле freq будет подсчитываться частота вхождения термина в документ (смотри рисунок). Заметим, что на основе морфологического анализа в таблицу Term заносятся лишь основы слов (PhraseBase), составляющих термин, т.е. всем терминам, отличающимся только падежными окончаниями, соответствует одна запись в этой таблице.
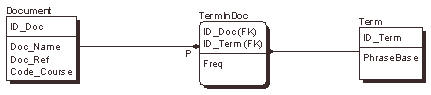
Рис.1. Логическая схема базы данных поисковой системы
Дадим некоторые пояснения к ER-диаграмме (в нотации IDEF1X), представленной на рис.1. Идентификатор связи Р между таблицами Document и TermInDoc означает «один или более», т.е. любой документ должен содержать термины. По сути дела это означает, что при регистрации документа в БД всегда должно выполняться построение его терминологической базы. Если, что маловероятно, при анализе документа термины обнаружены не будут, то данный документ просто не следует включать в БД.
Каждый конкретный термин из таблицы Term может содержаться в любом количестве документов. Допустимо также его отсутствие в таблице TermInDoc. Такая ситуация возможна в следующих случаях:
● частота вхождения термина в документы ниже выбранного порогового значения;
● таблицу Term можно пополнять «вручную», т.е. не выбирая слова из документов. Это может иметь место при формировании экспертами терминологической базы некоторой предметной области или при создании словарных баз для программ-переводчиков.
Атрибут Doc_Ref в таблице Document содержит ссылку на местоположение оригинала документа в файловой системе или сети.
Наконец, из таблицы TermInDoc удаляются все записи с частотой вхождения ниже некоторого порогового значения. То есть предполагается, что термины, которые встретились в документе, скажем, один раз, неадекватно характеризуют его содержание. Пороговое значение можно подобрать эмпирически. В этом случае пороговое значение представляет собой постоянную величину (например, единица). Недостатком постоянного порогового значения является то, что в небольших документах может вообще не оказаться терминов с частотой, выше порогового значения. Однако нельзя сказать, что такие документы вообще не несут никакой информации. Найти выход можно с помощью переменного порогового значения, принимающего некоторое значение в интервале между максимальной и минимальной частотой терминов в данном документе. Такое пороговое значение будет являться характеристикой документа. Кроме того, можно определить пороговое значение для совокупности документов [3].
При поиске будет проверяться только наличие термина (терминов) в таблице TermInDoc. Результатом выполнения запроса будет список документов, содержащих образец поиска, который действительно адекватно их характеризует, чем, как нам представляется, обеспечивается высокий уровень релевантности.
Как говорилось выше, список документов, отвечающих запросу, можно упорядочить в соответствии с частотой вхождения термина в документ или же в соответствии с весом данного термина (который можно определить, например, как отношение частоты вхождения термина в документ к числу терминов в документе).
Естественно, при данном подходе не на любые запросы будет получен ответ. Например, если образец поиска будет содержать только исключаемые из ПОД слова. Но, с другой стороны, какой смысл можно усмотреть в поиске документов по словам: «например» или «следовательно»? Кроме того, учет таких слов может привести к ошибочному выполнению запроса. В качестве примера рассмотрим поиск по словам «можно» и «термин». Ясно, что если поиск ведется по вхождению в документ, хотя бы одного из двух терминов, то возможно, что он весь будет состоять из документов, содержащих слово «можно» (причем с достаточно высокой частотой вхождения) и не содержащих слово «термин». Если же критерий поиска построен на вхождении в документ обоих слов, то релевантность такого поиска может вызвать сомнения. Не будет удивительным, если частота вхождения слова «можно» значительно превысит частоту вхождения слова «термин», в результате чего наверху списка окажутся документы, имеющие меньшую релевантность относительно слова «термин».
Следует отметить критичность данного алгоритма по отношению к точности определения части речи и правильности исключения «незначимых» слов.
В первую очередь сложность вызывает определение критерия, который позволил бы отличить существительное от прилагательного. Причем дело здесь не только в том, что существительное и прилагательное могут иметь в предложении одинаковые окончания, т.е. морфологический анализ в этом случае не сможет нам помочь, но и в том, что существительное и прилагательное могут быть представлены одним и тем же словом. Так слово «данные» в термине «экспериментальные данные» является существительным, а в словосочетании «данные нам в ощущениях» - прилагательное.
Для четкой идентификации части речи потребуется достаточно сложный синтаксический анализ. Его можно избежать, если оставлять в базе данных все отдельные слова и словосочетания в ПОД между разделяющими символами (смотри выше). По сравнению с первоначальным методом в предметный указатель попадут не только существительные, а также словосочетания, которые, возможно, будут содержать несколько терминов и то, что термином не является. Однако поставленная цель эффективного и релевантного поиска от этого не становится дальше. Мы ничего не теряем, поскольку терминологическая база может лишь незначительно увеличиться (отдельных слов станет больше, а словосочетаний - меньше).
В заключение скажем, что предложенный способ формирования поисковой базы данных документов позволит находить документы, когда поисковым образом является отдельное слово, несколько слов, словосочетание, а также слова, которые должны находиться поблизости друг от друга. В последнем случае анализируются словосочетания в терминологической базе данных.
Цитируемые источники
1. Игнатович Николай. DB2 Universal Database - ключевые характеристики. http://www.citforum.ru/seminars/cbd2000/cbd_day1_07.shtml
2. Игумнов Евгений. Основные концепции и подходы при создании контекстно-поисковых систем на основе реляционных баз данных. http://www.citforum.ru/database/articles/search_sys.shtml
3. Корнеев В.В., Гареев А.Ф., Васютин С.В., Райх В.В. Базы данных. Интеллектуальная обработка информации. - М.: «Нолидж», 2000. - 352 с.



Комментарии 0