Элементы математических методов компьютерного контент-анализа текстов

Очень часто контент-анализ путают с истолкованием текстов, реферированием текстов или с поиском информации в текстовых базах данных. На самом деле, изначально контент-анализ задумывался как строгий метод оценки текстов.
Шалак Владимир
кандидат философских нау, старший
научный сотрудник Института философии РАН
vaal_project@mail.ru
Появление контент-анализа было реакцией на возникшую потребность в создании объективных методов анализа текстов, результаты которых не зависели бы ни от личности исследователя, ни от того, где и когда эти исследования проводятся. Т.е. требовалось найти такие методы оценки текстов, которые не вызывали бы разногласий между исследователями и были воспроизводимы в любое время и в любом месте.
Существует целый ряд заблуждений относительно того, что же такое контент-анализ. Очень часто этот термин дословно переводят на русский язык как "анализ содержания" и считают, что все поняли, что это просто содержательный анализ текстов, их истолкование. В других случаях контент-анализ путают с реферированием текстов или с поиском информации в текстовых базах данных.
Никто не возражает против содержательного анализа текстов, их истолкования и пр. Просто не следует называть это контент-анализом, который изначально он задумывался именно как строгий метод оценки текстов.
Одним из определений контент-анализа является следующее: "Контент-анализ - это методика выявления частоты появления в тексте определенных интересующих исследователя характеристик, которая позволяет ему делать некоторые выводы относительно намерений создателя этого текста или возможных реакций адресата."(1)
Когда в качестве наиболее объективной оценки текстов избрали частоту появления в нем различных характеристик, казалось, что оптимальное решение найдено. Вскоре поняли, что не все так просто.
Если попросить двух экспертов подсчитать, сколько раз, например, было упомянуто имя президента в конкретном номере конкретной газеты, то скорее всего их ответы совпадут. Причиной расхождений может стать лишь невнимательность при подсчете. Но вот если попросить этих же экспертов подсчитать в той же газете количество слов с негативной окраской, то результаты будут явно отличаться. Более того, один и тот же эксперт на одном и том же материале в разные моменты времени даст разные ответы. Причина кроется в неоднозначности критериев. Эта проблема стоит настолько остро, что она даже отдельно изучается. Существуют специальные методы оценки надежности результатов ручного контент-анализа, когда можно доверять экспертам, а когда нельзя.
Отдельный вопрос - трудоемкость контент-анализа. Имеется интересная методика, позволяющая по тексту объемом от 80 до 150 слов получить достаточно полный психологический портрет автора. Анализируются в основном грамматические характеристики. На ручной анализ одного текста по той же методике уходит от 4 до 6 часов времени.
Гораздо хуже обстоят дела, когда приходится оценивать большие массивы текстов, поступающих непрерывно. Ручной контент-анализ становится просто невозможным.
Выходом в данной ситуации является разработка компьютерных методов контент-анализа. Невнимательность исключена; неоднозначность исключена, если критерии приняты; трудоемкость решается за счет быстродействия. Именно компьютерным методам контент-анализа текстов и посвящена настоящая статья.
Характеристиками или элементами содержания, по отношению к которым применяется процедура подсчета, могут быть отдельные слова, словосочетания, предложения, абзацы, тексты. При этом сами характеристики никогда не являются самоцелью. Они интересны лишь в той степени, в какой являются индикаторами происходящего во внеязыковой реальности. В этом заключается существенное отличие контент-анализа от методов квантитативной лингвистики, от методов статистического изучения языка.
Оценки частот
В контент-анализе самыми бедными по содержанию и в то же время самыми фундаментальными являются простые оценки частот. Примем следующее обозначение
f(c,t) - частота встречаемости характеристики c в тексте t.
В качестве примера рассмотрим частоту (количество) упоминания фамилии конкретного политика в конкретном СМИ (газете). Если речь идет о частоте упоминания в отдельном номере газеты, то практически никаких выводов сделать из этого нельзя. Совсем другое дело, если отслеживать частоты на протяжении определенного отрезка времени и сопоставлять их с поступками этого политика. Отсюда можно прийти к выводу о том, что в поведении данного политика привлекает внимание журналистов анализируемого издания. Можно подсчитывать частоту упоминания политика не в отдельных номерах газеты, а помесячно, и сопоставлять ее не с поступками, а с регулярно публикуемыми рейтингами политических деятелей. Это явится подходящим материалом для исследования на тему, как влияет и влияет ли частота упоминания политика в СМИ на его рейтинг. Гораздо больше информации даст одновременный подсчет частот упоминания не одного, а нескольких политиков. Появляется возможность сравнивать их между собой. В этом случае, например, корреляции частот может послужить основанием для более глубокого изучения общего в поведении анализируемых политиков.
Отдельные слова, как элементы содержания, являются частным случаем того, что в контент-анализе называется категорией. Категория - это множество слов, объединенных вместе по тому или иному признаку. Так, например, в качестве категории ЖИЛЬЕ может выступать группа синонимов {берлога, дом, жилище, жилье, логово, логовище, обиталище, обитель}. Другими примерами могут быть категории агрессивно окрашенной лексики АГРЕССИВНОСТЬ={бить, бушевать, грозить, назло, одолеть, погром, рычать,…} и позитивно окрашенной лексики ПОЗИТИВ= {благодарность, бодрый, вкусный, добро, нежный, няня, теплый, шутка, юмор, ясный,…}. Частота упоминания в тексте некоторой категории подсчитывается как сумма частот входящих в нее слов, т.е. если K - категория, то
![]()
Логической операцией, лежащей в основе создания категории, является определение через абстракцию. Вовсе не обязательно категория должна задаваться посредством заранее фиксированного списка слов. Иногда гораздо удобнее задать ее операционально. Примером такой категории может быть категория глаголов прошедшего времени. Определение принадлежности к ней будет заключаться не в сопоставлении с фиксированным списком слов, а в распознавании грамматических признаков глагола прошедшего времени.
Более сложными являются категории, состоящие не просто из отдельных слов, а из целых словосочетаний. Например, категория МОРЕ={Черное море, Средиземное море, Красное море, Балтийское море,…}.
Контент-анализ с использованием категорий позволяет оценивать тексты на более высоком абстрактном уровне. Результаты, получаемые с их помощью, качественно богаче. Возьмем, например, категории ПОЗИТИВ, НЕГАТИВ, АГРЕССИВНОСТЬ, АРМИЯ, ПОЛИТИКА, ЭКОНОМИКА, РАЗВЛЕЧЕНИЯ, ЗАКОН и подсчитаем частоты их встречаемости в интересующем нас издании на протяжении нескольких месяцев. Затем сопоставим, подсчитаем корреляцию, с ежемесячными рейтингами этого же издания среди различных социально-демографических групп. Положительные и отрицательные коэффициенты корреляции между частотами отдельных категорий и рейтингами подскажут, статьи какой тематики привлекают или отталкивают читателей той целевой группы, на которую рассчитано издание.
Как было сказано ранее, не только слова или словосочетания являются теми элементами содержания, частота которых может интересовать исследователя. Вместо того, чтобы подсчитывать частоту упоминания фамилии политика, можно подсчитывать частоту предложений, в которых упоминается политик. Очевидно, что в общем случае вторая величина будет меньше первой. Можно подсчитывать частоту абзацев, обладающих определенными признаками. Более крупными элементами являются целые тексты - статьи и книги. Например, подсчет частоты статей различной тематики позволяет делать выводы о редакционной политике издания. Аналогичный подсчет тематики книг, поступающих в научную библиотеку, позволяет судить о тенденциях в развитии науки, перспективных направлениях исследований и т.д.
Условные частоты
Простые частоты являются не самой подходящей оценкой текстов. Проблемы с ними могут возникнуть в том случае, если мы захотим сравнить разные по длине тексты. Например, пусть в некотором тексте t1 длиной в 1000 слов категория НЕГАТИВ встречается с частотой 20, а в тексте t2 длиной в 10000 слов - с частотой 100. Является ли пятикратная разница частот достаточным основанием для утверждения, что текст t2 окрашен более негативно, чем текст t1? Очевидно, что нет. Для вынесения такого утверждения необходимо сравнивать не простые частоты, а условные, т.е. доли которые составляет категория НЕГАТИВ в первом и втором тексте.
Условную частоту характеристики c в тексте t обозначим посредством pr(c,t). Вычисляется она по формуле
pr(c,t)=f(c,t)/L(t), где L(t) - длина текста t
В зависимости от того, что принято за элементы содержания, в качестве длины текста может быть взято общее количество в нем слов, количество предложений, количество абзацев и т.д. Обычно, если характеристика - это отдельное слово или категория слов, то и в качестве длины текста берется количество слов в нем.
В нашем примере pr(НЕГАТИВ,t1)=20/1000=0,02 больше, чем pr(НЕГАТИВ,t2)=100/10000=0,01. Т.е. более негативно окрашенным является не второй, а первый текст.
Иногда вместо условных частот удобнее использовать оценку процентного содержания. Для этого просто умножают условную частоту на 100 и тем самым получают процентное содержание.
Переход от использования простых частот к условным значительно расширяет сферу применимости методов контент-анализа. Если раньше все наши примеры имели дело с текстами одинаковой длины, то теперь это ограничение снято. Теперь мы можем сравнивать разные по длине статьи, разные по объему издания и пр.
Нормы
До сих пор для того, чтобы делать какие-то выводы, нам требовалось оценить как минимум два текста. Затем эти оценки либо сопоставлялись между собой, либо соотносились с некоторыми событиями в реальном мире, и на основании этого делались определенные выводы.
Представим, что перед нами поставлена задача классификации текстов по медицинской и немедицинской тематике. Причем требуется, чтобы это делал не человек, а компьютер. Решение довольно очевидно. Текст должен быть отнесен к медицинским в том случае, если частота встречаемости медицинских терминов в нем существенно выше, чем в обычной речи. Для этого следует сформировать категорию медицинских терминов Km и сопоставить ей условную частоту встречаемости в обычной речи pr(Km,речь), которую назовем нормой для категории Km. При анализе конкретного текста t подсчитывается условная частота pr(Km,t). Если она существенно больше нормы pr(Km,речь), то текст t относят к к медицинской тематике. Аналогичная процедура может быть применена для дальнейшей классификации текстов по различным разделам медицины. Достаточно лишь сформировать соответствующие категории и сопоставить им нормы, но уже не на основании обычной речи, а на основании анализа представительной выборки различных медицинских текстов. Задача по формированию норм облегчается тем, что в настоящее время существует довольно много частотных словарей, относящихся к различным сферам человеческой деятельности, и нормы можно извлекать из них. Нормы можно вычислять и для отдельных людей. Они могут оказать весьма полезны, например, для определения душевного состояния человека. Так превышение в речи относительно личной нормы частоты категории НЕГАТИВ может свидетельствовать о том, что человек находится в дурном настроении.
Важно подчеркнуть, что понятие нормы всегда относительно. Для сугубо гражданского человека норма частоты употребления агрессивно окрашенной лексики одна, для профессионального военного - другая. Нормы могут меняться не только от одной профессионально определенной группы людей к другой, но и со временем. Причиной тому служат исторические изменения в жизни общества, отмирание старых идей и появление новых, заимствования из других языков, влияние на лексический состав языка таких факторов как общественная мораль и пр.
Более строго понятие нормы можно определить следующим образом. Имеется некоторое множество текстов T, которые объединены вместе по определенному признаку. Нас интересует норма характеристики c для T. Так как множество текстов T может быть слишком велико или недоступно целиком, то из него берется представительная конечная выборка V и уже для нее вычисляется условная частота pr(c,V). Это и будет принято в качестве нормы характеристики c для T, которую мы обозначим посредством nr(c,T). Норма характеристики c для множества текстов T - это ожидаемая условная частота ее встречаемости в произвольном тексте, принадлежащем данному множеству. Для представления того, как сильно отличается от ожидаемой частота встречаемости характеристики c в конкретном тексте t из T, используются следующие оценки:
pn(c,t,T)=pr(c,t)/nr(c,T) - во сколько раз отличается pr(c,t) от nr(c,T)
pd(c,t,T)=[[pr(c,t)-nr(c,T)]/nr(c,T)]*100 - на сколько процентов отличается pr(c,t) от nr(c,T).
Аналитика в первую очередь интересуют те тексты, для которых оценка pn(c,t,T) существенно отличается от 1, или же оценка pd(c,t,T) существенно отличается от 0. При этом дополнительного уточнения тербует термин существенно отличаться. На помощь приходит аппарат математической статистики. Обычно считают, что характеристика c имеет в тексте t биномиальное распределение с вероятностью nr(c,T). Пусть реально в тексте t характеристика c встретилась pr(c,t)*L(t) раз в то время как ожидалось nr(c,T)*L(t). Исходя из свойств биномиального распределения легко подсчитать, насколько мала вероятность того, что для произвольного текста ti абсолютная величина abs(pr(c,ti)-nr(c,T))*L(ti)>=abs(pr(c,t)-nr(c,T))*L(t). Обычно, если вычисленная таким образом вероятность не превышает порога 0,05 (или 0,01), считается, что отклонение реальной частоты от ожидаемой существенно, т.е. не является случайным.
На практике гораздо чаще используют оценку, вычисляемую по формуле:
z(c,t,T)=[pr(c,t)-nr(c,T)]/SQRT[pr(c,t)*(1-pr(c,t))/L(t)]
Это разница двух условных частот, нормированная по стандартному отклонению. Ее имеет смысл использовать лишь в том случае, если pr(c,t)*(1-pr(c,t))*L(t)>=2,5. Эта оценка хорошо известна психологам и социологам. Именно с ее помощью обосновываются методы вычисления баллов многих психологических тестов. Если z(c,t,T)>=1,96, то мы сразу можем сказать, что вероятность данного события не превышает 0,05. Если же z(c,t,T)>=2,58, то вероятность этого события еще меньше и не превышает 0,01. Из формулы видно, что данная оценка прямо пропорциональна корню квадратному из длины текста t. Именно поэтому ее можно использовать для определения того, что данное событие не является случайным, но не для оценки того, насколько велико отклонение реальной частоты от ожидаемой. К сожалению, многие психологи и социологи не различают этого и потому их выводы очень далеки от научности. В применении к методам психологического тестирования замечательную критику по этому вопросу дал А.Г.Шмелев(2).
Контекстный анализ
Основная идея контекстного анализа заключается в том, что анализу подвергается не весь текст, а лишь некоторая выборка из него, являющаяся контекстом употребления характеристики c. Есть много способов задать контекст. Например, для слова (характеристики) w в качестве его контекста мы можем взять все предложения (абзацы, статьи, книги), в которых оно встречается. Вместо предложений мы можем считать контекстом по одному или более слов слева и справа от каждого вхождения w в текст.
Если текст t рассматривать как множество предложений, а предложение s рассматривать как множество слов, то контекст категории C в тексте t можно определить как
ctx(C,t)={s-{w}: w входит в C, w входит в s, s входит в t}.
Выделенный контекст может анализироваться как самостоятельно, так и относительно основного текста. Во втором случае основной текст служит источником норм, которые затем используются при анализе контекста. Т.е. во втором случае для произвольной категории K мы интересуемся условной частотой pr(K,ctx(C,t)) и сравниваем ее с нормой nr(K,t), вычисляемой как pr(K,t-{C}), где t-{C}={s-{w}: w входит в C, s входит в t}
Дополнительно к этому мы можем выделить множество слов
col(C,t)={w: pr(w,ctx(C,t)) существенно больше pr(w,t-{C})}
В англоязычной литературе по контент-анализу такое множество называется collocation категории C. Отношение существенно больше валидизируется с помощью аппарата математической статистики по аналогии с тем, как это описывалось выше. Множество col(C,t) содержит много полезной информации о категории C. Например, col({змея},речь) будет содержать такие слова как яд, кусать, ползать, пресмыкающееся,…, а в col({Путин},СМИ) войдут слова Владимир, президент, Кремль, Россия,….
Связи категорий
Мы можем интересоваться не только оценками данного текста по отдельных категориям, но и их взаимосвязями.
Любому тексту t, рассматриваемому как последовательность предложений , и категории C может быть сопоставлен булев вектор b(t,C)=, где vi=1, если для некоторого w из C w входит в si, и vi=0 в противном случае. На множестве векторов легко определить логические операции. Для двух векторов b(t,Ci)= и b(t,Cj)= они определяются следующим образом
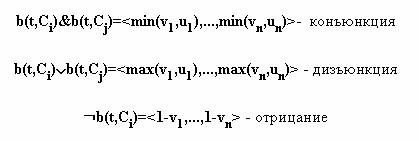
Затем на множестве векторов можно ввести логические отношения совместности, противоречия, подчинения и пр. Очевидно, что таким образом задается некоторая логическая модель предметной области, о которой идет речь в тексте, или же модель когнитивной карты, присущей автору текста. Дальнейшее изучение этих моделей проводится с использованием аппарата классической, многозначной или вероятностной логики высказываний.
Особый интерес представляет анализ и визуализация отношений между категориями с использованием аппарата многомерного шкалирования, кластерного и факторного анализа.
Определим на множестве категорий (булевых векторов, сопоставленных категориям) функцию близости. Для каждого вектора b(t,Ci)= вычисляется оценка
![]()
Тогда коэффициент корреляции для булевых векторов вычисляется следующим образом
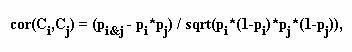
а функцию близости можно определить как
![]()
Также в качестве оценки близости двух категорий часто используется метрика Хемминга, определяемая посредством формулы
![]()
Контент-мониторинг
Если анализу подвергается массив упорядоченных во времени текстов, поступивших из одного источника, речь идет уже не о простом контент-анализе, а о контент-мониторинге текстовой информации. В этом случае, появляется дополнительная возможность применить математический аппарат многомерного регрессионного анализа, аппарат анализа временных рядов, методы технического анализа.
Так, например, контент-мониторинг пресс-релизов РАО ЕЭС позволил обнаружить закономерности, связывающие различные психолингвистические характеристики текстов с последующими биржевыми изменениями курса акций компании. Применение этих же закономерностей к анализу пресс-релизов компании ENRON позволило обнаружить ее неблагополучие задолго до наступившего осенью 2001 года банкротства. То, чего не заметили аудиторы, было обнаружено с использованием методов контент-мониторинга.
Другой пример контент-мониторинга связан с анализом пресс-релизов оборонного ведомства США и выявлением индексных показателей, свидетельствующих о подготовке и проведении военных операций.
Интересные результаты дает контент-мониторинг динамики избирательных кампаний с целью предсказания победителя или внесения в нее необходимых корректив.
Шкалированные категории
До сих пор под категорий понималось некоторое множество характеристик, слов или словосочетаний, объединенных вместе по тому или иному признаку. В контент-анализе используются и более сложно устроенные категории, которые могут быть названы шкалированными. В них объединены характеристики, каждой из которых дополнительно приписана одна или несколько оценок по заранее фиксированным шкалам.
Так, например, А.Г.Шмелев с коллегами провел многолетние исследования по выявлению лексики, используемой для обозначения различных личностных черт. Было построено многомерное по числу выявленных личностных черт пространство и каждому из используемых слов была сопоставлена точка в этом пространстве. Координаты слова являются его оценками по каждой из шкал (осей) пространства. Всего было выявлено пятнадцать устойчивых шкал - оценка эмоциональная, оценка интеллектуальная, активность, сила эмоциональная, сила физическая, раздражительность, практичность, нравственная оценка, ригидность, демонстративность, деятельность, скрытность, эгоизм, утонченность, необычность. Оценка текстов по этим шкалам может заключаться в вычислении средней оценки и сравнении ее с нормой.
Другой известный пример шкалированных категорий - это звукобуквы А.П.Журавлева(3), позволяющие по набору осгудовских шкал оценивать фоносемантический образ русскоязычных текстов и слов.
Заключение
Перечисленные в статье математические методы компьютерного контент-анализа текстов далеко не исчерпывают всего многообразия. Например, ничего не было сказано о таком важном направлении в контент-анализе, как алгоритмические методы автоматического формирования категорий. Это отдельная и большая тема, которая требует своего подробного рассмотрения. Мы надеемся обратиться к ней в одной из последующих работ.
Практически все упомянутые в данной статье методы реализованы в компьютерной экспертной системе ВААЛ. Она существует вот уже десять лет и успела зарекомендовать себя как надежный и удобный инструмент контент-анализа текстов.
Источник: Проект ВААЛ
Похожие статьи



ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 1
Несмотря на довольно интересное содержание статьи, встречаются формулы с явными ошибками и неточным соответствием тексту.
Пример: в одной формуле контекст категории определен, как не содержащий слов самой категории, а в другой формуле идет отсылка к частоте встречаемости слов категории в контексте, которая по определению равна 0.