Поиск в ECM
В первом приближении эта задача кажется простой, особенно для пользователей Интернета, не представляющих себе жизнь без поисковых сервисов. Та же строка запроса и кнопка «Найти». На самом деле, все несколько сложнее.
Бушмелев Сергей, ИТ-аналитик DIRECTUM
Трудно представить себе ECM систему без функционала поиска. Я бы даже сказал, что невозможно. В первом приближении эта задача кажется простой, особенно для пользователей Интернета, не представляющих себе жизнь без поисковых сервисов. Та же строка запроса и кнопка «Найти». На самом деле, все несколько сложнее. Чтобы понять насколько, нам нужно детализировать понятие контента, который хранится в ECM-системе. Поскольку ECM система – это разновидность корпоративных систем, данные, которые накапливаются в этой системе, являются артефактами бизнес-процессов. Существует несколько классификаций бизнес-процессов и контента, образующегося в процессе их выполнения. Мне больше нравится идея, предложенная аналитиками Forrester. Весь контент можно условно разделить на Transactional и Business. Опять возникает задача интерпретации этих терминов, я их понимаю следующим образом:
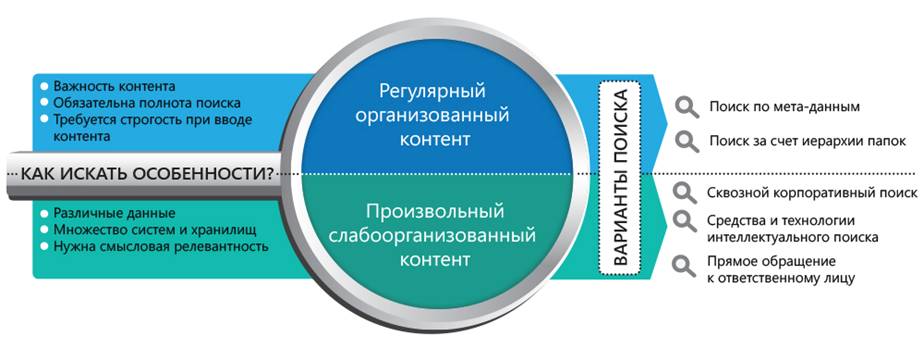
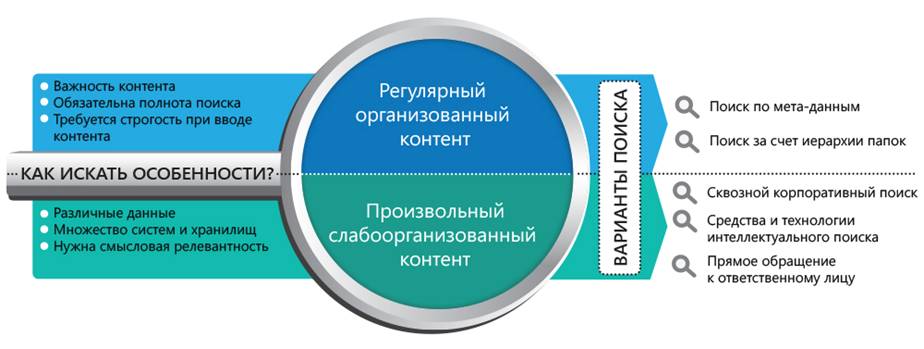
● Регулярный организованный контент, образующийся в результате выполнения транзакционных бизнес-процессов. Применительно к ECM системе это будут приказы, договоры, акты, заявления, поручения, письма. Эта информация в системе дополняется значительным объемом метаданных: наименованиями документов, проектов, лиц и организаций, с ними связанных, датами, регистрационными номерами и т.п.
● Произвольный слабо организованный контент, который образуется в результате совместной или самостоятельной работы в рамках различных проектов или задач. Примером такой информации будут протоколы и итоговые документы по результатам совещаний, аналитические отчеты, результаты исследований и экспериментов, зафиксированные результаты мозговых штурмов и т.п. Состав метаданных здесь менее информативен и регулярен.
Для обоих типов контента существуют свои сценарии и, соответственно, свои методы поиска.
Поиск регулярного организованного контента
Сценариев поиска организованного контента множество, как универсальных, так и специализированных. С ходу можно придумать поиск документа по регистрационному номеру, поиск договоров по конкретному контрагенту, поиск приказов за прошлый месяц. Задавая условия поиска, инициатор поискового запроса надеется получить список всех договоров, когда-либо заключенных с данным контрагентом, или же ищет все приказы, выпущенные в прошлом месяце. Ключевое слово здесь «все», то есть требуется обеспечить максимальную полноту поиска. Неполный список результатов поиска может стать причиной не просто ошибки, а вполне ощутимого ущерба для организации: экономического, правового, репутационного. Например, если какой-то договор не вошел в результаты поиска, сотрудник может не включить его в расчет задолженности или реестр платежей, что в итоге приведет к экономически неблагоприятным последствиям. Если на запрос регулирующего органа будет представлен не полный перечень документов, это может повлечь штрафные санкции со стороны регулятора. Не найденное в  результате выполнения поискового запроса письмо может вызвать репутационные или даже экономические издержки. Таких примеров, демонстрирующих, насколько важна полнота результатов поиска, можно привести множество.
результате выполнения поискового запроса письмо может вызвать репутационные или даже экономические издержки. Таких примеров, демонстрирующих, насколько важна полнота результатов поиска, можно привести множество.
Перед организацией встает задача обеспечения полноты поиска. Решается эта задача совокупностью организационных и технических методов. Из организационных методов я бы упомянул своевременную и полную регистрацию входящих, исходящих и внутренних транзакционных и организационно-распорядительных документов, организацию системы классификации документов.
Из технических методов стоит упомянуть создание иерархии папок, обеспечение полноты заполнения и достоверности метаданных. Метаданные играют ключевую роль, так как часть документов может вовсе не содержать текстовых данных (нераспознанные скан-образы документов).
Крайне желательно, чтобы классифицирующие метаданные (например, проект, контрагент, ответственный сотрудник) были представлены справочным типом данных. А сами справочники должны быть полными, актуальными, не имеющие дуплицирующих данных.
Основными методами поиска будет поиск по метаданным и навигация по иерархической структуре папок. Перейдя в нужную папку, пользователь получает весь перечень документов данного класса. Или же, задав поисковые критерии для метаданных – реквизитов документов, пользователь получит полный перечень документов, соответствующих поисковым критериям.
Стоит также отметить, что результаты поиска формируются в соответствии с правами доступа данного пользователя. Поэтому, чтобы обеспечить полноту результатов поиска, необходимо обеспечить пользователю доступ ко всей информации, положенной ему по должности, в том числе вновь создаваемой. На помощь администратору системы придут политики, шаблоны, группы и роли пользователей.
Резюмируя вышесказанное, если перефразировать девиз компании Яндекс «Найдется всё», то для поиска регулярного организованного контента это должно звучать так: «А ничего и не терялось». :)
Поиск произвольного слабо организованного контента
По терминологии Gartner к этому типу контента наиболее близким понятием является Business Content. Это всевозможные информационные объекты, создаваемые в ходе основной бизнес-деятельности организации.
Если основным продуктом организации является информация, то она структурирована, и ее управление и поиск осуществляются по сценариям и с использованием техник, перечисленных в предыдущем разделе. В большинстве организаций информационные артефакты оказываются побочным продуктом, но именно они формируют так называемые корпоративные знания.
Это только на словах это звучит цельно, а на практике корпоративные знания состоят из множества слабо связанных между собой данных (документы, электронная почта, переписка в задачах, логи чатов, блоги, вики и масса других информационных объектов). И поиск в этой вселенной может значительно отличаться от поиска организованной информации.
Начнем с признания того факта, что сотрудники по возможности стараются избегать этой операции, и, в первую очередь, обращаются за помощью к тем сотрудникам, которые, по мнению первых, могут подсказать, какие информационные материалы есть по тем или иным темам и вопросам.
Одна из причин, по которой это происходит – это потенциальное отсутствие прав доступа на искомую информацию. В организации может вестись масса проектов, проистекать множество бизнес-процессов, и информационные материалы могут быть открыты только участникам рабочей группы. И полная просьба может звучать, как не только предоставить список искомых материалов, но и дать право доступа к ним.
Но прямое обращение к компетентному сотруднику не всегда удается осуществить. Причин может быть масса: незнание, кто из сотрудников обладает этими знаниями и может помочь или сотрудник может к тому времени уволиться. Придется искать нужную информацию самому.
Для слабо организованного контента так же важна полнота результатов поиска, но в этом данном случае в этот термин будет вкладываться немного другой смысл. Полнота здесь – это соответствие желанию пользователя, а не просто формальным поисковым критериям. Пользователю нужно найти материалы, касающиеся определенного вопроса, а не просто документы, где в названии или тексте документа есть определенная подстрока. Если результат поиска не полный, то это может повлечь принятие неоптимального управленческого решения. Если результаты поиска будут, наоборот, избыточные, то это также осложнит поиск нужной информации в море посторонних знаний.
Как и в предыдущем случае, полнота результатов поиска обеспечивается как организационными, так и техническими методами. Создание корпоративной базы знаний – большая отдельная тема, здесь же хотелось поговорить о технических методах.
Не секрет, что корпоративные знания разбросаны по множеству, если не всем информационным системам организации. Поэтому в ряде ситуаций не обойтись без средств сквозного корпоративного поиска (Google Appliance, Microsoft FAST, HP Autonomy, 3DS Exalead и другие решения). Такое решение позволяет искать информацию одновременно сразу в нескольких информационных системах.
Другой аспект, который нельзя обойти вниманием, это то, что в этих сценариях резко возрастает роль полнотекстового поиска. Причем для обеспечения полноты результатов это должен быть не примитивное сравнение строк, а интеллектуальный поиск. Базовые механизмы поиска уже включает некоторые элементы интеллектуального поиска, например, словоформы. Тем не менее, простор для развития направления есть. С ходу можно предложить следующие техники, увеличивающие эффективность поиска:
● Поиск с учетом синонимов и таксономий. Позволит производить расширенный поиск: некоторые материалы, имеющие отношение к вопросу, могут вовсе не содержать искомого слова, но его синонимы.
● Поиск с учетом вариаций, например разные варианты транскрипции иностранного слова. Например, в одном и том же репозитории могут быть собраны материалы, которые содержат не только англоязычное название Galaxy, но и «русские» варианты его написания – «Галакси», «Гэлакси» и т.д. Механизм поиска, который бы включил в результаты все варианты транскрипции, обеспечил бы большую полноту результатов.
● Поиск с учетом ошибок. Механизм может предложить, что в поисковой фразе содержатся ошибки, и предложить поиск по исправленному варианту.
● Поиск на нескольких языках. Думаю, что будет востребовано в транснациональных организациях.
● Поиск на естественном языке. Это позволит извлечь больше информации из поисковой фразы и так же обеспечить большую полноту результатов.
Как видите, поиск в ECM-системе – это далеко нетривиальная задача. Необходимо совместить иногда диаметрально противоположные подходы, чтобы обеспечить и полноту результатов поиска, и их релевантность поисковым запросам. Это также простор для применения различных интеллектуальных технологий. Возможно, что недалеком будущем наличие таких технологий будет серьезным конкурентным преимуществом.
Источник: CNews
Похожие статьи


ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 7
По утверждению компании Яндекс, это не так. Поиск на естественном языке - не более, чем модная фишка. Да и то, модная не сейчас, а много лет назад. Вообще, если интересен поиск произвольного контента - рекомендую изучить наработки Яндекса в этой области (они очень много интересного выкладывали в публичный доступ).
Может мы, обделенные Apple русскоязычные пользователи считаем Siri модной фишкой, но к продуктам Apple и к технологии Siri активно присматриваются автопроизводители, развивая концепцию eyes-free.
Ну, и Gartner на своей фирменной "загогулине" поместил Natural-Language Question Answering в область Technology Triggers.
IMHO профессионалы на "естественном языке" запросы не составляют - это удел юзверей :)
Хорошая обработка запросов на естественном языке сулит значительную коммерческую выгоду, - только не нужно представлять её как что-то дико передовое в научном плане :)
Сергей, открою большой секрет: Siri - это НЕ поисковая система. В части поиска (а я напомню, что пост этот о поиске) она всего лишь умеет передавать запросы настоящим поисковым системам (Google, Yahoo, Яндекс, WolfamAlpha). И их всех этих систем только WolfamAlpha не вырос еще из коротких штанишек и не наигрался в поиск на естественном языке. Но при всех его умениях он ничуть не угрожает бизнесу больших поисковых систем. Которые, как раз-таки давно уже наигрались в поиск на естественном языке и пришли к выводу, что даже массовому пользователю это не надо. Уметь понимать и обрабатывать естественный язык - надо, но совсем в другом смысле (если так сильно лень искать материалы Яндекса, то могу потом пересказать на пальцах).
Но вот распознавать естественный язык, как это умеет Siri, конечно же, надо. Только это к поиску не относится. Google точно так же распознает мой естественный язык для того, чтобы я мог писать SMS и твиты голосом.
Наталья, Вы правы. Речь идет о консьюмеризации корпоративных информационных систем. Для ECM-решений этот тренд, думаю, также характерен. Дело не в новизне технологий, а в их удобной реализации в пользовательских продуктах. Путь Apple :)
Так и в ECM-системе аналог Siri может передавать запросы движку. Для пользователя неважно, как это устроено внутри - он общается с системой посредством речевого интерфейса.
Перечитал исходную статью еще раз. Не нашел ни слова про Siri или речевой поиск.