
Большие данные и их место в ECM

Большие данные и их место в ECM
Термин Big Data (большие данные) находится на слуху так давно, что кажется уже каждый, близкий к информационным технологиям человек, знает его смысл. Термин употребляется при любом удобном случае, зачастую Big Data даже используют для обозначения большого объема информации. В результате у людей нет четкого понимания того, что такое большие данные на самом деле и почему методы работы с ними должны отличаться от тех, что применяются в традиционных СУБД.
Что же все-таки скрывается за большими данными? Каковы их отличительные черты? Есть ли место для больших данных в ECM? Ответы на все эти вопросы и не только, вы найдете в статье.
Определение больших данных через их признаки
Чтобы понять, когда данные переходят в разряд больших, нужно выделить их отличительные признаки.
Первый и самый очевидный признак – это объем. Действительно, большие данные должны быть большими. Счет, как правило, идет на терабайты и петабайты. Однако объем является относительным показателем, все зависит от решаемой задачи и области применения. Именно этот показатель многих вводит в заблуждение, так как не существует четкой границы, после которой можно однозначно заявить «мы работает с большими данными».
____________________________________________________________________
Немного увлекательной статистики из мира больших данных:
Google обрабатывает более петабайта данных в день — это примерно в 100 раз больше всех печатных материалов Библиотеки Конгресса США.
Facebook* может похвастать более чем 10 миллионами загрузок новых фотографий ежечасно.
800 миллионов ежемесячных пользователей YouTube каждую секунду загружают видео длительностью более часа.
Еще в 2000 году количество информации, хранящейся в цифровом формате, составляло всего одну четверть общего количества информации в мире. К 2013 году количество хранящейся информации в мире составило 1,2 зеттабайта, из которых на нецифровую информацию приходится менее 2%.
____________________________________________________________________
Второй отличительный признак – разнородность данных. Кроме того, что данных должно быть много, они должны быть разными, иметь различный тип, характер, представление. Например, возьмем некий абстрактный аппарат, собирающий биометрические данные группы людей: пульс в минуту – целочисленное значение, время замера – дата, место замера – координаты с геолокационного датчика, температура тела – вещественное значение, звуковой сигнал – набор вещественных значений записанных в определенном формате и так далее.
Третий признак – отсутствие явной связи между частями данных. Если не понятно, как одни данные связаны с другими, и как из этого можно извлечь пользу – это хорошо! Прелесть больших данных заключается в том, что зачастую сразу нельзя увидеть их полезность, она проявляется позже, когда мы начинаем обрабатывать и анализировать их. Находятся неожиданные связи и зависимости, позволяющие реализовать инновационный функционал и взглянуть на старые задачи по-новому.
И четвертый, на мой взгляд, один из важнейших признаков – набор данных должен являться полным объемом всей возможной информации, касающейся того или иного процесса. Что такое полный объем данных, поясню на примере. История всех перелетов с информацией о пассажирах, самолетах, аэропортах и ценах на билеты, конкретно взятой авиакомпании с момента её основания – полный объем данных. Если взять те же самые данные, но за последний месяц – это будет не полный объем данных, а выборка. И это важно, большие данные не могут быть выборкой, это всегда полный объем данных.
Большие данные – это совокупность подходов, методов и инструментов по работе с полным объемом разнородных явно не связанных между собой данных, с целью извлечения выгоды для бизнеса.
Аспекты больших данных в КИС
Все действия связанные с большими данными сводятся к управлению и использованию.
Управление состоит из трех основных задач:
1. Хранение. В каком виде хранить данные и как к ним обращаться.
2. Разделение. Предварительное структурирование. Данные нужно подготовить, даже если предполагается, что они будут обработаны в «сыром» виде.
3. Удаление. Когда данные нужно удалять и нужно ли их удалять вообще.
Существует множество подходов и технологий, призванных решить эти задачи. Тут можно говорить о NoSQL-концепции организации баз данных, являющихся распределенным хэш-таблицами в оперативной памяти, а так же о массовом распараллеливании вычислений в рамках MapReduce и Hadoop, и о прочих известных тегах. Это техническая составляющая и в рамках данной статьи она представляет для нас меньший интерес, нежели использование больших данных.
Именно глубокое понимание принципов использования позволяет добиться ощутимых результатов для бизнеса. Для того чтобы эффективно применять большие данные, нужно мыслить иначе, отказаться от сложных выборок и перейти к простым корреляциям. Уйти от необходимости во всем искать причинно-следственные связи, отвечать на вопрос «что именно», а не «почему и как». Данные можно обрабатывать снова и снова. Они представляют собой то, что у экономистов принято называть «неконкурирующим» товаром, которым могут пользоваться несколько человек одновременно без ущерба друг для друга. Сбор информации имеет решающее, но не исчерпывающее значение, так как основная ценность находится в использовании, а не управлении.
Ближе к ECM. Генераторы больших данных
Чтобы знать, где искать большие данные в ECM, нужно знать, что их может генерировать. Люди, процессы и время – это три основных генератора. Если изобразить их в виде шкал трехмерного графика и установить определенные пороговые величины, то данные организаций, чьи координаты выходят из треугольника, потенциально являются большими. Допустим, 1000 человек – штат организации, 100 процессов – количество бизнес процессов организации и 10 лет – время существования организации. Эти величины являются относительными, однако они близки к современным реалиям отечественного сегмента ECM-рынка. Чем дальше организация выходит за площадь графика, тем активнее ей нужно задумываться об обработке своих исторических данных с целью извлечения определенной выгоды.
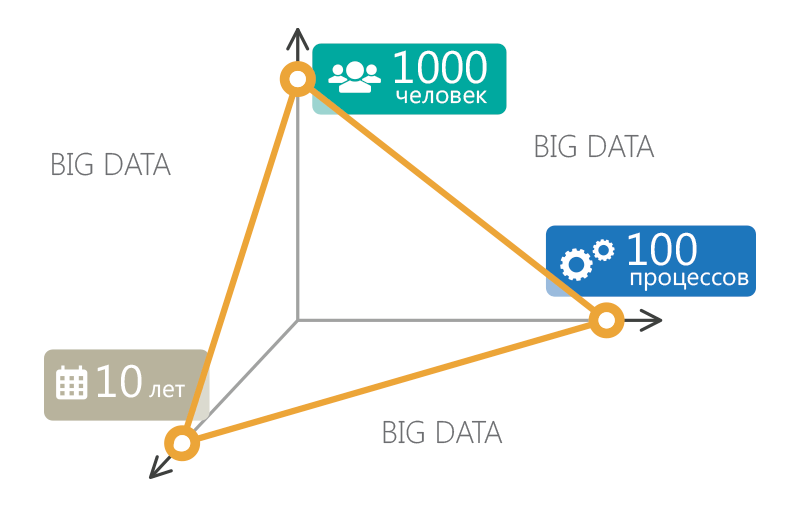
Рис. 1 Территория больших данных
Все данные ECM систем можно разбить на четыре группы:
1. Контент сам по себе – это тела электронных документов и сопровождающие их метаданные.
2. Данные о процессах – виды процессов, параметры с которыми они работают, результат их работы, факты отказов, а так же информация сопровождающая их. Яркими примерами процессов являются: workflow, автоматический ввод документов, различные административные скрипты и так далее.
3. «Цифровой след пользователя» – это история работы пользователей с объектами системы, взаимодействие с компонентами и службами. След генерируется, когда пользователь заходит в систему со своего гаджета, просматривает и редактирует документы, оставляет комментарии, выполняет поручения, и при любых других действиях, которые могут логироваться. Чем больше система знает о пользователе – тем лучше для Big Data.
4. Справочные данные – записи. Неоднозначна полезность и применимость данной группы в рамках больших данных. По своей сути, справочные данные – это выборка в чистом виде, например справочник организаций или населенных пунктов.
Ниже представлены статистические данные ECM систем различных по масштабу компаний, «попадающих» в Big Data (по рис. 1), с момента внедрения:
Стоит отметить, что здесь «цифровой след» – это лишь факт того что пользователь авторизовался в системе, за ним находится вся история работы (просмотр документов, работа с компонентами и т.д.)
Из графиков видно, что даже в средних компаниях накопилось достаточное количество данных, чтобы можно было говорить о потенциальных возможностях применения Big Data в ECM.
Решение реальных задач в ECM
Основная причина дефицита решений на основе больших данных в ECM сфере заключается в том, что вендоры не видят реальных задач, в которых можно эффективно применить концепцию Big Data. Для того чтобы найти эти задачи нужно пойти от существующих проблем различных по масштабу компаний.
К таким проблемам можно отнести:
• выявление узких мест в процессах с целью оптимизации;
• неэффективное использование времени, повторное решение однотипных задач;
• неэффективные и избыточные процессы;
• информационная безопасность, утечка данных представляющих интеллектуальную собственность;
• оценка и управление человеческими ресурсами;
• законодательство.
Перечень этих проблем может изменяться, все зависит от специфики конкретной компании. Однако многие проблемы являются общими для всех, и существует возможность создавать универсальные или требующие минимальной конфигурации решения на основе больших данных.
Рассмотрим проблему выявления узких мест в процессах более детально. Допустим, в компании существует некий постоянный бизнес процесс, при этом состав участников является динамическим, т.е. на одном и том же этапе могут быть задействованы разные люди с одинаковыми ролями. Собрав и проанализировав всю статистику по этому процессу с момента его первого запуска (сам процесс, смежные процессы, люди участвующие в процессах и т.д.), можно построить прогностическую модель, которая бы при очередном запуске процесса советовала наиболее подходящие параметры (состав участников, сроки, маршрутизация), тем самым оптимизируя его.
Так же актуальной проблемой является информационная безопасность. Основная стоимость многих компаний находится не в материальных активах, а в информационных. Система мониторинга на основе больших данных способна анализировать «цифровой след» всех пользователей системы и искать корреляции, свидетельствующие о всплесках подозрительной активности. Этими всплесками могут являться: массовый экспорт документом из системы, активная работа с документами напрямую не связанными с профессиональной деятельностью, взаимодействие с системой в нерабочее время и т.п. С учетом того, что в крупных компаниях количество пользователей может составлять десятки тысяч человек, применение больших данных кажется более чем обоснованным.
Для решения подобных задач вендорам понадобится новый класс сотрудников – специалистов по данным (data scientist). По сути, это люди обладающие знаниями в области data mining, data analysis (математическая статистика, поиск и интерпретация данных, алгоритмы работы с данными). Ещё одним полезным качеством для таких специалистов будет способность прогнозировать и предугадывать потенциальную полезность тех или иных данных, что позволит найти неожиданные зависимости и привнести интеллект в систему.
Перспективы больших данных в ECM
Если обобщить, то ничего по-настоящему нового в концепции больших данных нет. При работе с ними используются известные статистические методы и принципы простых корреляций. Возросший интерес к Big Data вызван тем, что у крупных компаний накопилось так много данных, что они теоретически могут приносить выгоду для бизнеса уже сейчас. Однако искать массовое применение для Big Data пока рано. Вендорам необходимо сконцентрироваться на поиске реальных проблем у своих клиентов, которые могут быть решены с помощью больших данных.
* - организация, признанна экстремистской на территории РФ
Комментарии 4
Мне кажется, это не является атрибутом больших данных. А вот неназванное непрерывное появление новых данных с неотрицательной динамикой — это признак больших данных. Если мы возьмём данные о продажах одного сетевого магазина за месяц, как понять, большие ли они? Если это кофе с собой, то, наверное, не очень. Если это IKEA, то должны быть внушительными. Может быть, даже большими по определению. Если возьмём данные о продажах со всех существующих сетевых магазинов — будут ли тогда данными большими? А если это всего лишь кофе с собой?
Забавный факт: недавно в ходе опроса выяснилось, что специалисты по работе с данными — счастливые люди.
Я думаю, что не стоит привязываться к какой-то конкретной области. Дело в том, что говорить о больших данных стоит только тогда, когда из них можно извлечь пользу, до тех пор - это просто много байтов. Возьмем ту же IKEA, да за месяц у них накапливается много данных, но их будет не достаточно для того чтобы найти какие-то полезные корреляций, не будет того с чем сравнивать эти данные и в чем искать зависимости. Чем больше данных собрано относительно какого-то процесса - тем эффективнее будет применение Big Data. Анализировать нужно полный объем данных, с момента их первого появления.
А чем отличается корпоративный контент от тех же самых данных Маркета и почему уже обработанные, частично структурированные и помещенные в хранилище данные не могут быть большими и приносить пользу? По сути история переписок внутри компании - это те же комментарии к товарам, а таймлайн продуктивности сотрудника - это аналог графика цен.
Огромный плюс данных в том, что их можно обрабатывать снова и снова, возможно на данный момент эти данные сами по себе бесполезны, но через 10 лет их накопится столько, что с их помощью можно будет решить самые неожиданные задачи.
Что только подтверждает актуальность этого направления = )
"Большие данные" - это не столько свойство, присущее самим данным, сколько особенность методов их обработки. Объём данных вообще на самом деле вторичен; главным является использование инновационных алгоритмов для совместной обработки разнородных данных и выявления неочевидных зависимостей. Всё, что успешно обрабатывается традиционными методами, к большим данным не относится по определению ;)
Поэтому совсем не удивительно, что, в зависимости от целей и способов их обработки, одни и те же данные могут рассматривать в одних случаях как большие данные, а в других - просто как куча байтов :)
Ещё одна деталь: высококачественные "малые" данные всегда лучше и эффективней, чем "большие данные", но, чтобы в этом убедиться, каждый исследователь должен хотя бы разочек самостоятельно "наступить на грабли" ;)
Да, отчасти это так есть. Однако я бы не стал говорить о алгоритмах обработки больших данных как о инновационных, основной принцип использующийся в Big Data - это принцип корреляций, который едва ли можно назвать инновационным. Преимущественно все методы используемые в Big Data - это всем известные методы математической статистики. Единственным радикально новым в BigData является принцип массового распараллеливания вычислений и разнесение их по различным узлам кластера (например MapReduce).
А вот тут я не согласен. Многие задачи решаемые в Big Data попросту не могут быть решены с помощью ограниченных наборов данных, более того Big Data это инструмент для получения тех самых "малых" эффективных данных. Большие данные и классические выборки не являются взаимозаменяемыми, они существуют параллельно друг другу.