
Запросы на естественном языке (NLQA) в ECM. На примере.

Запросы на естественном языке (NLQA) в ECM. На примере.
Не так давно был написан пост, в котором я изложил свои соображения о применимости запросов на естественном языке (NLQA) в ECM-системах. Главная мысль состоит в следующем: поиск информации через запросы на естественном языке по критериям – достаточно неэффективное занятие, сценарии нужно рассматривать шире, а проблему глубже. Ниже поясню, на основе чего были сделаны такие выводы.
Перед моей небольшой группой стояла задача сделать прототип так называемого умного поиска в рамках конкретной ECM системы. Стояла цель научить систему выдавать результаты по поисковым запросам пользователей, сделанным на естественном языке.
Чтобы понять, что ищут люди, было проведено небольшое исследование, где мы опросили людей и проанализировали их поисковые запросы. Результатом анализа стал набор шаблонов, покрывающий большинство поисковых сценариев опрошенных людей. Все они, так или иначе, отвечают на вопросы: «какие объекты найти» и «кто, что и когда делал с объектом (документом, папкой, workflow item и т.п.)». Обнаружилось, что в запросах могут фигурировать имена сотрудников или названия организаций, в качестве временных интервалов используются такие нечеткие понятия, как «недавно», «на прошлой неделе», «в этом году» и т.п.
Для распознавания русскоязычных запросов мы применили готовый парсер Tomita, реализованный Яндексом в виде свободной программы. Tomita позволяет на внутреннем программном языке определить шаблоны для выделения структурированной информации из текста. В итоге, например, из поискового запроса на естественном языке «какие документы вчера редактировал Иванов Иван» Tomita извлекает следующие факты: ищем – документы, время – вчера (dd.mm.yyyy), операция – редактирование, субъект операции – Иванов Иван.
Мы подготовили несколько десятков шаблонов и встроили «умный поиск» в систему.
Что можно найти, используя «умный поиск»? Ниже представлен ряд примеров.
Запрос: Найди все заявления, которые я редактировал в этом месяце.
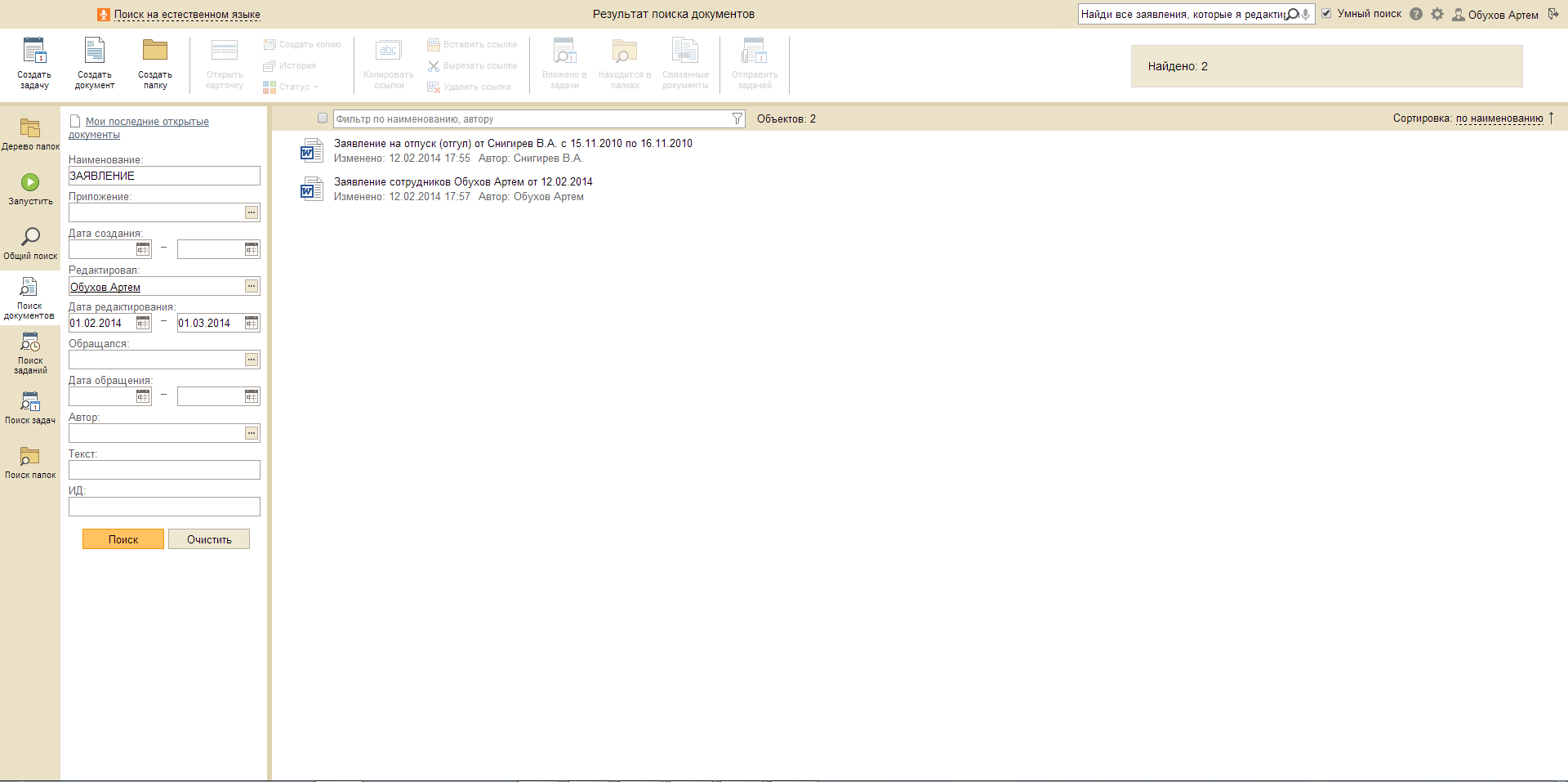
Запрос: Покажи все счет-фактуры, просмотренные мной 12 февраля.
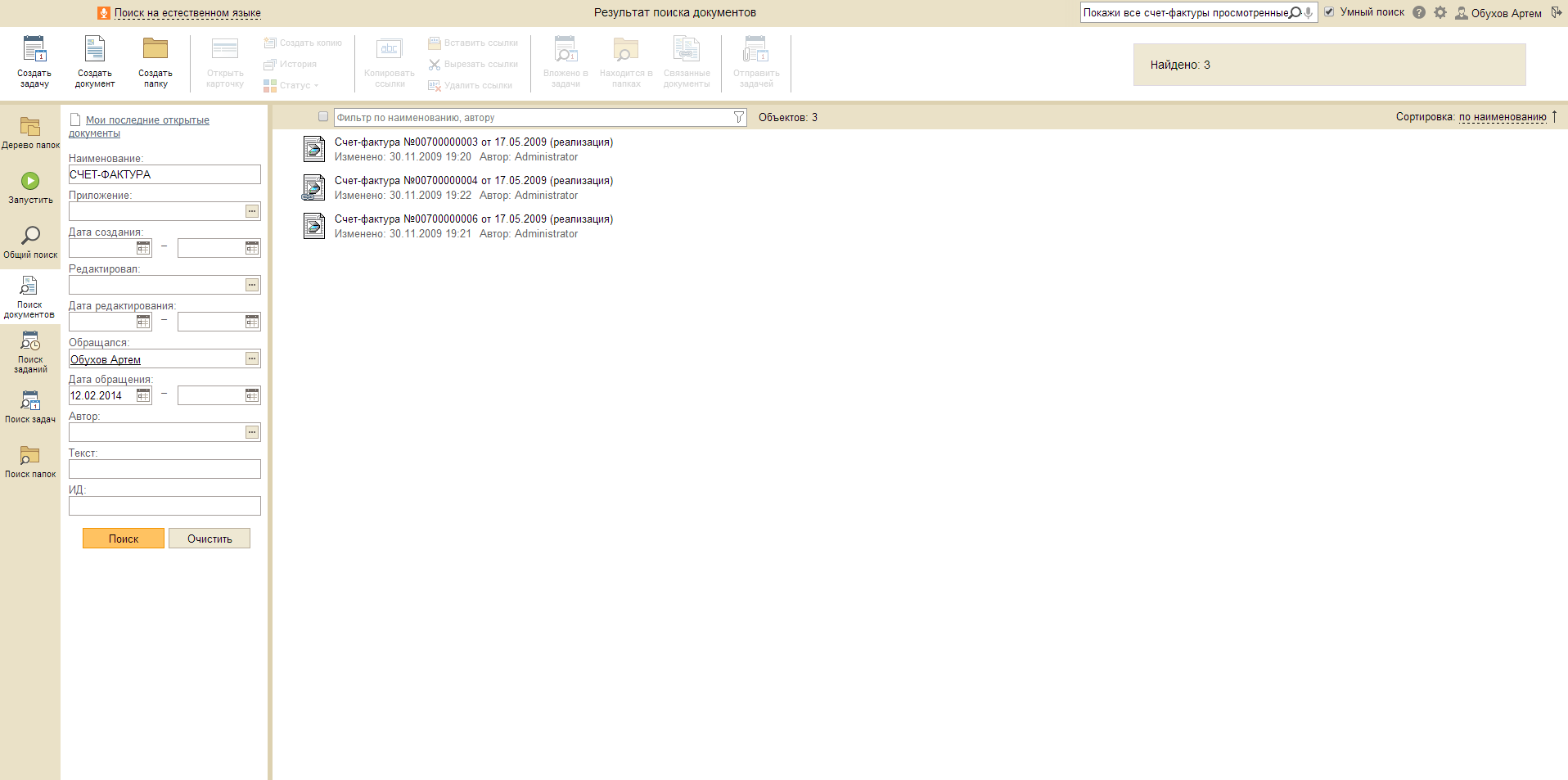
Запрос: С чем я работал в этом году.
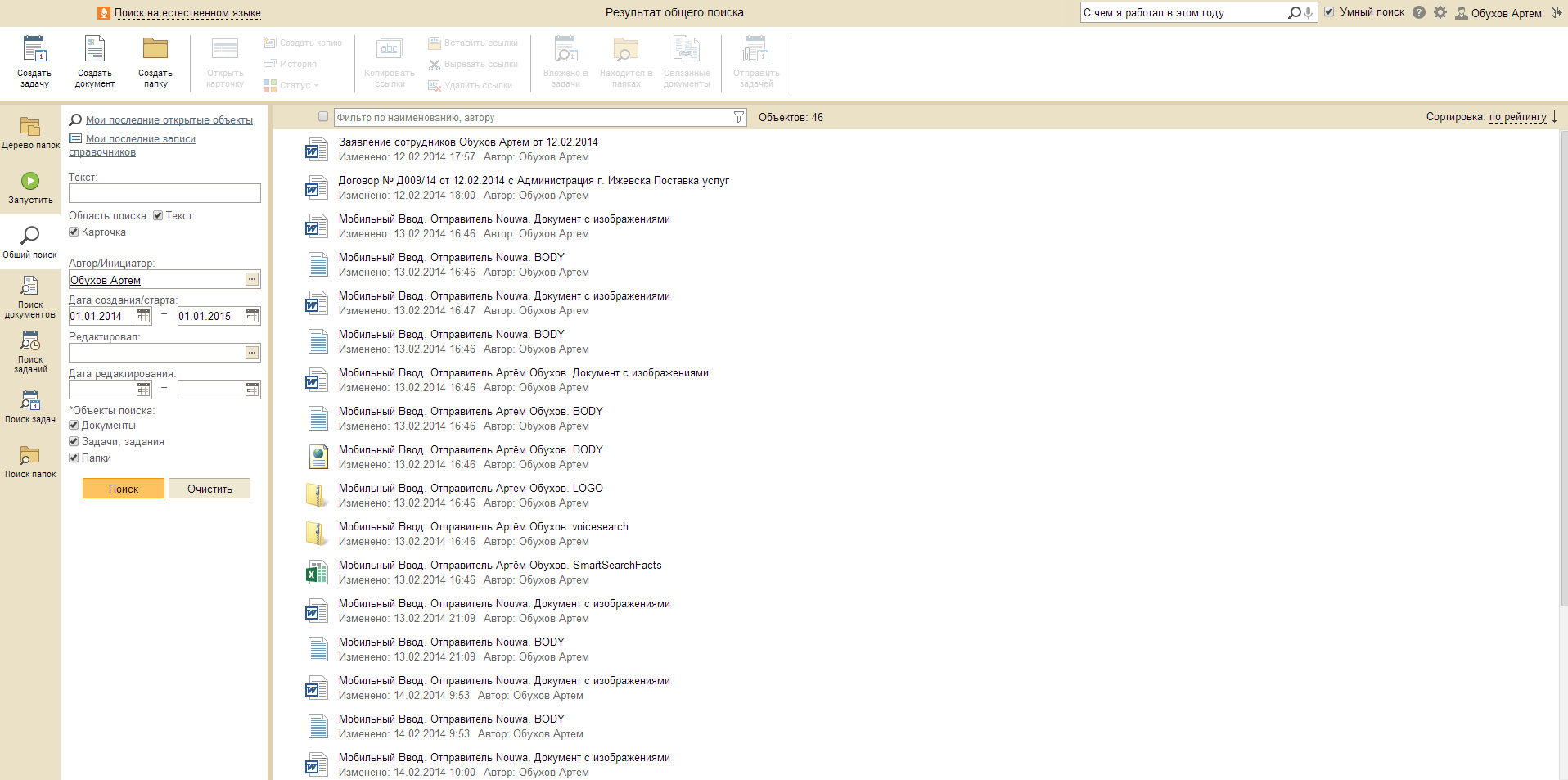
В целом распознаются такие запросы, как:
- Найди мне все договорные документы, которые я редактировал на прошлой неделе.
- Все заявления отдела маркетинга за февраль.
- Мои недавние созданные документы.
- Задачи, инициированные Обуховым Артемом в прошлом месяце.
- Объекты, с которыми я недавно работал.
- Покажи все входящие письма просмотренные мной 17 июля.
- Найти задания, отмененные Сидоровым в 1998 году.
- С чем я вчера работал.
- Найти документы содержащие заказы автомобилей.
- Найти созданные мной папки с задачами.
- Выдать папки с заданиями, с которыми я работал год назад.
- И т.д.
Решение прошло опытную эксплуатацию в реальных «боевых» условиях, и сейчас видно, что у него есть ряд проблем: технических и «сценарных», пользовательских.
Технические проблемы связаны с некачественным распознаванием имен сотрудников и организаций (учет падежей и т.п.). С этим можно бороться, вводя и наполняя словари.
Гораздо хуже проблемы сценарные.
- Пользователю сложно вводить так много текста. Если применять голосовой ввод (что тоже было опробовано), то получаем, во-первых, дополнительные технические проблемы с качеством распознавания, а во-вторых, сложно представить себе человека, разговаривающего с настольным компьютером всерьез. Это было бы, возможно, более естественно при работе с небольшим мобильным устройством, где клавиатурный ввод затруднен, но это еще следует подтверждать опытным путем.
- Пользователь не знает, какие запросы он вообще может формировать. Увы, количество шаблонов пока недостаточно, чтобы распознать все возможные запросы. Пока пользователю явно удобнее вводить критерии искомых документов в удобную поисковую форму: и быстрее, и все критерии перед глазами.
- Если и применять «умный поиск», то к запросам менее формальным и более смысловым, ориентированным на содержание документов. Например, «найти все договоры по закупке оргтехники за прошлый месяц» или «в каком протоколе заседаний мы касались вопроса уборки мусора в парке». Увы, это пока нереально.
Думаю, основной вывод в том, что в таком виде умный поиск пока слабо применим. Впрочем, если вам видны какие-то задачи, где он реально полезен, или есть мысли, как подобный NLQA-механизм можно было бы усовершенствовать, я готов это обсудить!
Похожие статьи


ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 3
Артем, спасибо за статью! Теперь все, что вы постулировали в прошлой статье, стало понятным (понятны корни этих утверждений). Теперь, собственно, есть предмет для обсуждения.
Отвечая на ваше последнее предложение
я, наверное, полностью соглашусь - в текущем виде данный механизм мало пригоден.
Единственное применение, того что вы описали - это голосовое управление для мобильных устройств (наверное, наиболее близкий по предметной области к СЭД и уже реализованный механизм, это голосовое управление в Exchange - там только помимо голосовых команд есть еще и обратная связь: надиктовка заголовков, текстов писем, ...), но на сколько это нужно в СЭД?
На самом деле я бы предложил посмотреть на предложенную задачу более широко - можно ли сказать что современные системы ECM, как-то управляют содержимым хранимых документов?
И тут я не открою Америки, если скажу, что в почти 100% случаев все управление сводится к манипулированию атрибутами, т.е. структурированной частью информации, а практически все атрибуты - результат ручного ввода, дополнительно к заносимому телу документа. Т.е. знания СЭД о содержимом документа, практически всегда ограничиваются тем минимумом, который ввел пользователь.
А, это, в свою очередь, обычно очень куцый набор - номер, даты, несколько справочных полей и все... (я не говорю про случай, когда на основе ECM строится, например, учетная система).
Вот если взять ваш последний пример "не берущихся" запросов.
Чтобы найти такие документы, нам достаточно иметь представление о предмете договора. Вот только формализовать понятие "предмет договора" на несколько порядков сложнее чем, скажем, "дата документа" (и то, люди путаются, что именно считать датой документа для разных типов документов) или "контрагент" (и опять же - здесь ошибки не редкость), а вот на сколько это нужно - вопрос, да еще какой.
Для целей учета - вроде ни к чему, практически всегда в отчетных документах будет стоять ссылка на конкретный номер и дату договора (типа "в рамках договора №453-б от 21.12.2005 г."). Для целей делопроизводства тоже вроде ни к чему - там в основном нужно знать до какого момент нужно хранить документ, а когда уже его можно (нужно) уничтожать. Связать это с предметом договора напрямую вряд ли получится.
На самом деле, многие документы содержат куда больше информации, чем мы выносим в метаданные. Почему мы их (метаданные) не храним? В основном, потому что их получение, это сложно (пример с правильным заполнением "предмета договора" это еще цветочки) и дорого (мы вынуждены дважды повторять одну и ту же информацию, а зачастую - еще и менять её по несколько раз, если меняется документ).
В принципе, ситуация немного улучшается. Я знаю, что некоторые организации уже идут по пути структуризации хотябы самых основных (и простых) своих документов: кто-то пробует использовать для этого механизмы e-forms, кто-то экспериментирует исходным хранением документов в структурированном виде и формировании текста документа просто как финального отчета (или как более удобного механизма для визуализации).
Кстати, раз уж пришлось к слову :) - самые читаемые из моих статей на EJ, это статьи про создание электронных форм на осове Word
Но это еще первые шаги и до состояния когда на вопрос "изображение Романов Михаила" будут выданы, фотографии из СЭД, системы кадрового учета, открытых страниц соц. сетей, с сайтов и порталов компании, из документов, справочников, ...
Михаил, действительно, документы содержат больше полезной информации, чем мы храним в структурированном виде. И вопрос тут скорее не по NLQA части, а по извлечению полезных структурированных данных из большого объема всевозможного контента хранимого в современных СЭД. Было верно подмечено, необходим глубокий анализ содержимого документов, чтобы однозначно истолковать факты, которые могут быть представлены по разному.
Например, Google и Yandex ежедневно прокручивают терабайты неструктурированных данных и извлекают из них полезные факты, которые успешно применяют в своих сервисах и приложениях (rabota.yandex и пр.). Когда ECM вендоры начнут разрабатывать подобные решения для своих продуктов и агрегировать всю полезную информацию в виде связных фактов, тогда можно будет говорить о возможности создания эффективных NLQA механизмов.
Приведенный сценарий "изображение Романов Михаил", превосходно демонстрирует то, к чему необходимо стремиться при создании системы вопросов-ответов на естественном языке = ).
Ну... кому как не вам - представителю Research-направления одного из ведущих ECM-поставщиков в России - определять когда это начнет воплощаться в жизнь? :)
Правда, лично я пока испытываю по поводу перспектив появления интеллектуальной обработки документов в ECM-системах сдержанный скепсис: мне кажется, что на текущий момент создать за приемлемый срок (год-два) коммерчески успешное решение не реально - технологии не того уровня. А вкладываться в разработку не пойми чего (а сейчас именно так - даже отдаленные перспективы не очень ясны) на годы врятли кто-то захочет. Все предпочитают заниматься более насущными, а главное понятными вещами.
Самое интересное, что мне известны несколько частных решений по внутренней автоматизации, сделанные без привлечения вендоров ECM и их партнеров (и даже не на базе какого-либо ECM-продукта. Как минимум одно решение точно целиком собственная разработка), которые в вопросах управления именно содержимым документ продвинулись очень не плохо. Но это частные решения, которые, скорее всего, никогда не покинут стен компании, для которой они были созданы.