
Оценка применимости Compreno для ECM-задач. Часть I: Поиск информации
Оценка применимости Compreno для ECM-задач. Часть I: Поиск информации
Compreno — платформа анализа и понимания текстов на естественном языке, разработанная компанией ABBYY. На ней базируется ряд продуктов, а именно: Intelligent Search, Smart Classifier и InfoExtractor. Среди сценариев их использования есть и те, что могут быть применены для решения задач в области управление корпоративным контентом.
Compreno для ECM — это попытка решить три основные задачи: умный и эффективный поиск (Intelligent Search), автоматическая классификация контента (Smart Classifier) и автоматическое извлечение структурированных данных из текстов документов (InfoExtractor).
Что из этого получилось, какие есть ограничения и возможности, в чем заключается практическая выгода для бизнеса и какова цена всего этого? В этой статье будут даны ответы или, как минимум, высказано экспертное мнение по этим вопросам. Все ниженаписанное основано на результатах исследования и тестирования продуктов базирующихся на возможностях платформы Compreno.
Применение Compreno для поиска информации в ECM
Для того чтобы понять, как Intelligent Search может помочь в улучшении поиска ECM-системы, нужно разобраться в том, какие сценарии поиска существуют и как они устроены, а так же выяснить, что из этого покрывается базовым функционалом среднестатистической системы.
По сути все поисковые сценарии — это комбинации трех составляющих: способ поиска — то, как мы формируем поисковой запрос; область поиска — это набор объектов системы к которым мы применяем запрос; ожидаемый результат — сколько и каких объектов мы хотим увидеть в результате.
Можно выделить шесть основных способов поиска:
- Запрос по атрибутам (key — value). Например, «Тип документа = договор, Дата создания = вчера».
- Запрос вхождения в тело документа:
- По образцу. Когда мы ищем точную фразу с незначительными морфологическими или синтаксическими отклонениями. Например, вспоминаем, что был документ, где фигурировала фраза «ABBYY Compreno Pricing».
- По смыслу. Когда ищутся все данные, связанные по смыслу с запросом. Например, хотим найти всю информацию, связанную с архитектурой Compreno (процесс проектирования, технические проекты, презентации и т. д.).
- Запрос/вопрос на естественном языке:
- Запрос. Включает в себя упоминание атрибутов со значениями и часть для поиска по вхождению. Например, «Все договоры нашей организации за 2013 год по продаже модуля «Канцелярия».
- Вопрос. Например, «Где был описан порядок лицензирования продукта X».
- Навигация по смысловым (онтологическим) категориям:
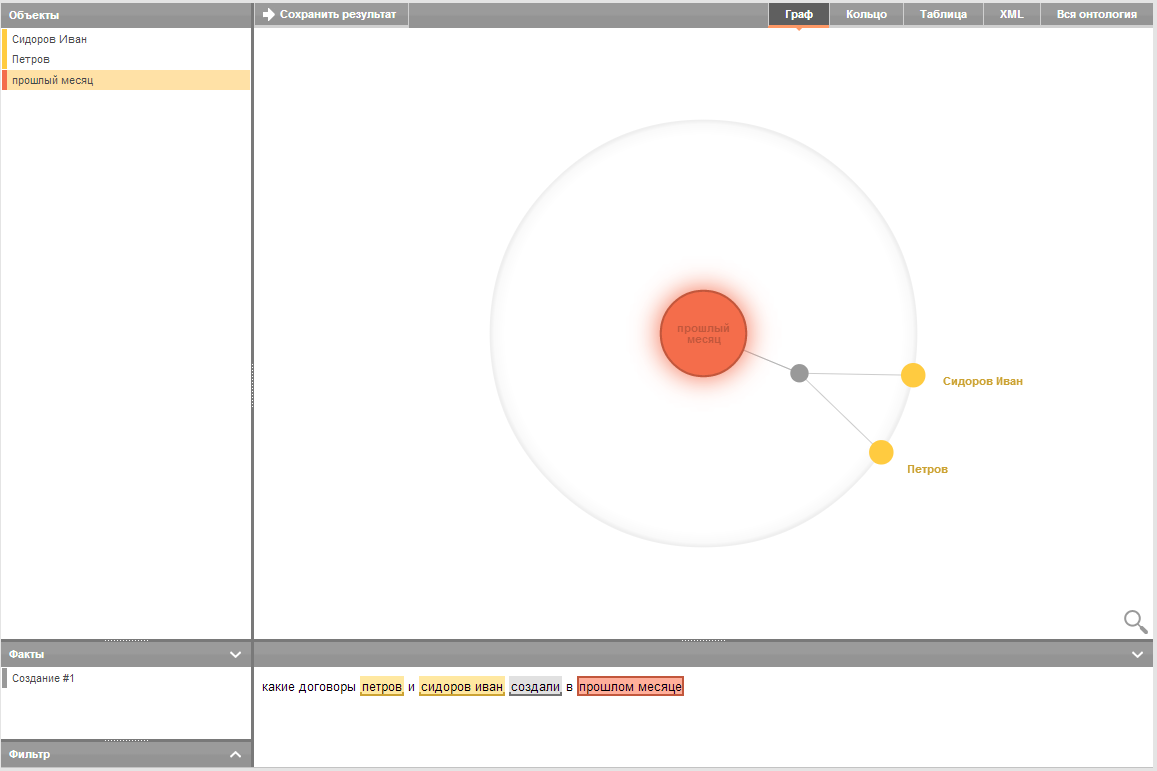
- Навигация по сущностям (объектам). Например, последовательное уточнение запроса по выделенным из документов категориям «Договор», «Петров», «Москва» выдаст все договоры, заключенные Петровым или с Петровым, с упоминанием города Москва.
- Навигация по фактам (отношениям). Например, запрос по факту «является стороной в договоре» с уточнением названия организации поможет быстро найти нужный документ.
- Навигация по папкам. Визуальный поиск среди набора папок («Договоры» / «Договоры на закупку» / «Договоры на закупку в ООО «Буревестник»).
- Навигация по связям с документами:
- Поиск по формальным связям документа (договор — приложения).
- Поиск по связям, содержащимся в тексте (договор — нормативные акты, которыми руководствуется договор).
Три области поиска:
- Все документы системы.
- Папка или набор папок.
- Результаты предыдущего поиска (уточнение поиска).
И три основных категории результатов:
- Конкретный документ (например, договор с организацией за определенную дату с определенным номером).
- Подборка документов (например, все методические документы, связанные с управлением проектами).
- Информация:
- Часть документа (например, подсвеченное предложение из текста документа, где явно дается ответ на запрос)
- Сгенерированный ответ. Ответ на вопрос может отсутствовать во всех данных системы в явном виде, но генерируется на их основе (например, как составить заявление на отпуск).
Помимо всего этого на процесс поиска влияет ряд фич, которые может поддерживать поисковой движок информационной системы:
- Учет словоформ.
- Учет переводов и транслитераций.
- Исправление ошибок в тексте поискового запроса.
- Учет синонимов.
- Учет плотности вхождения (расстояние между словами в тексте).
Теперь посмотрим какие сценарии уже покрывается базовым функционалом среднестатистической ECM-системы.
- Всевозможные виды атрибутивного поиска, с возможностью поиска во всем объеме данных, в определенном каталоге системы. Результат выдается в виде конкретного документа или подборки документов.
- Навигация по всему объему данных или определенным каталогам и подборкам документов через проводник системы.
- Поиск по связям между объектами во всем объеме данных, в каталоге, подборке (через связанные объекты и гиперссылки).
- Полнотекстовый поиск, т. е. запрос по вхождению — образцу во всем наборе данных, в каталоге или подборке.
- Комбинация сценариев 1 и 4.
Оценим, что нам может дать применение Compreno и Intelligent Search в частности:
- Запросы с вхождением по смыслу.
- Реализация поиска в результатах поиска на основе найденной в них информации (постепенное уточнение). Этот вид поиска особенно привлекателен, весьма эффективный и интуитивно понятный.
- Навигация по смысловым категориям (онтологиям, в терминах Compreno), в т. ч. использование их при построении запроса.
- Реализация ряда «фишек», а именно:
- Учет словоформ (альтернатива тому, что дает MS SQL).
- Исправление ошибок (альтернатива существующим open source реализациям).
- Учет переводов и транслитераций.
- Учет синонимов.
- Учет плотности вхождения. Релевантность на основе расстояния между целевыми словами.
Все это в комплексе выглядело бы как хорошее подспорье для улучшения существующих механизмов поиска, если бы не ряд ограничений с которыми мы столкнулись в процессе работы с решением:
- Не расширяется словарь синонимов. Например, КАС в нашем контексте, это «Комплексная Автоматизированная Система». Compreno этого не знает, и обеспечить это знание не представляется возможным из-за отсутствия соответствующих инструментов в поставляемом API.
- Не расширяются виды сущностей. Существует набор доступных базовых сущностей (персона, организация и т. д.), однако среди них нет важных для предметной области СЭД понятий, например сущности «документ» (договоры, заявления).
- Низкая релевантность при работе со смысловыми категориям (онтологиями). Например «договоры ТНК», Compreno поймет что ТНК — это организация (хотя не факт, см. п.1), но этого недостаточно, так как будут найдены все документы содержащие эти слова (сущности), а нужен только документ — договор.
- Низкая скорость индексирования. Например, 2500 стандартных документов (docx, xlsx, pdf) индексировались несколько дней на выделенном сервере с хорошей вычислительной мощностью. Если речь пойдет об индексировании целой базы, к примеру 100 000 документов и среднее время на 1 документ — 5 минут, то это займет 8333 часа или 347(!) дней. Станция обработки, на которой проводились замеры, согласно консоли управления Compreno, имеет 3 обработчика (4 ядра процессора). По заявлению представителя ABBYY для индексации такого объема документов рекомендованная вычислительная мощность 100 ядер процессора, индексация займет 4 дня.
- Низкая скорость поиска относительно существующих в ECM-системе механизмов.
- Выделение онтологий нестабильно (например, «Бик» — это не организация, а «Синицын» и «Синицыну» — одно и то же лицо).
Если мы закроем глаза на описанные выше недостатки, то Compreno и Intelligent Search в частности, могут помочь в улучшении качества поиска в ECM, приблизить его к поиску «как в google». Однако это палка о двух концах, и сейчас я объясню почему.
Поиск в корпоративной информационной системы отличается от поиска в интернете, это связано и с характером решаемых задач, и с характером хранимых данных, и с объемом данных.
Используя поиск КИС мы не хотим узнать рецепт борща или дату выхода новых «Звездных Войн», мы ищем конкретный документ или набор документов (объектов), которые обладают легко формализуемыми критериями и признаками, на основе которых и строятся поисковые запросы. Отсюда вытекает ряд особенностей, например, чрезмерное обобщение и учет ненужных синонимов может увеличить число выдаваемых по запросу документов и тем самым уменьшит такой важный для ИПС показатель как точность поиска, снизив тем самым общую релевантность результатов.
Кроме того, стоит понимать, что Intelligent Search это не компонент, который «вшивается» внутрь вашей КИС, а отдельный инфраструктурный модуль стоящий рядом. Отсюда и основные ограничения: необходимость держать отдельные сервера, медленный поиск (относительно поиска напрямую из платформы КИС), проблемы с безопасностью (учет прав доступа, маршрутизации контента между поисковым сервером и основной базой данных, полнотекстовые индексы хранятся за пределами системы), медленная индексация (в этом виновата не только описанная выше проблема, но и особенности алгоритмов анализа Compreno, они имеют большую вычислительную сложность).
Резюмируя вышеизложенное можно заключить, что ряд ограничений наверняка получится обойти при доработке и кастомизации Compreno Intelligent Search под конкретную систему, однако, это потребует дополнительных финансовых затрат, что прибавит стоимости и без того прожорливому продукту. Кроме того, решение в том виде, в котором его видели мы, явно требует оптимизации в плане скорости работы и требуемых ресурсов. Нужно понимать, что Compreno не решает критически важных и новых бизнес-задач в области поиска корпоративной информации, а лишь частично модифицирует и преображает существующие инструменты.
При этом Compreno Intelligent Search — это определенно новое слово в поисковых технологиях, и если ваша компания готова взять на себя все риски и затраты по внедрению, в будущем вы можете стать владельцем инновационной поисковой платформы.
В следующей части статьи будут рассмотрены продукты Smart Classifier и InfoExtractor, отвечающие за решение задачи интеллектуального ввода данных.
Варианты представления связей объектов граф и кольцо.
Похожие статьи


ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 4
Это как?
Можно конкретный пример? Я представляю, что такое уточнение поиска было даже несколько попыток выпуска подобных поисковых систем, но как-то не получили они признания. Может у вас есть свежие идеи...
Ну и по поводу выявленных недостатков
- ожидаемо, если честно. Откровенно говоря, у текущих систем поиска нет проблем с охватом области поиска - люди научились составлять достаточно правильные запросы. Проблема отбросить лишнее.
А вот это
и это
- фактически ставят крест на использовании данного продукта.
Могу привести такой пример. Допустим нам нужно найти определенный договор, с определенной компанией (мебельная фабрика), но при этом мы не помним названия компании, точных имён и дат. Задаём начальный поисковой запрос "Мебельная фабрика" и указывает что ищем документ с типом "договор", в результате получаем кучу договоров (>200 к примеру), помимо документов возвращаются и значения онтологий представленных в них, они разбиты на смысловые группы (города найденные в текстах, персоны , даты и т.п.). Мы помним, что фабрика расположена в городе Ижевск, выбираем его и число документов сужается до тех, где фигурирует этот город. Далее мы можем увидеть знакомую фамилию (опять же из числа оставшихся документов) и т.д., до тех пор пока выборка не станет настолько малой, чтобы мы без проблем выбрали нужный договор.
Возможно пример выглядит не очень реальным, но общий смысл такого подхода к поиску информации думаю понятен. Стоит отметить, что такой подход серьезно нагружает сервер, поэтому целесообразно использовать его в связке с In-Memory технологиями. При разработке прототипа мы создавали зеркало данных системы в отдельной In-Memory БД (которая периодически синхронизируется с основной базой) и при поиске работали с ним, не нагружая основной сервер. Благодаря In-memory поисковые запросы обрабатывались достаточно быстро, что позволяло "плавать" по данным практически в real-time. Но опять же, это порождает дополнительные требования к инфраструктуре, делая её ещё дороже. Предположу, что это одна из основных причин того, почему такие поисковые системы "не взлетают".
Это очень серьезные ограничения и нас они тоже смутили. Представители ABBYY предложили использовать их вычислительные мощности расположенные в облаке, но я думаю вряд ли крупные компании будут в восторге от того, что их данные будут летать по интернетам туда-сюда, а небольшой и средний бизнес не пойдёт на такое усложнение инфраструктуры ради модернизации поисковых механизмов. + Мы тестировали эти продукты год назад, в ABBYY говорили, что они занимаются оптимизацией скорости работы, возможно они и смогли добиться каких-то улучшений.
Артем, спасибо за статью.
Compreno, конечно, революционная технология и если оценивать ее применимость к ECM-системам, нужно, на мой взгляд, отталкиваться от портрета потребителя ECM-системы на основании такой технологии. Во-первых, это должен быть очень крупный заказчик, во-вторых, у него должно быть очень много документов, в третьих, ему должно быть критически важно анализировать все эти документы и принимать на их основе решения.
Кроме того, разработчики ECM- систем, скорее всего должны будут пересмотреть свои продукты в сторону адаптации под способности Compreno, поскольку применение продукта меняет и логику выполнения поиска, как выше описал Артем, и логику восприятия его результатов.
Небольшой и средний бизнес скорее всего не увидит потребности в таком инструменте и не почувствует эффект от его применения, это уже не говоря о том, что вряд ли это будет ему по карману (если мы говорим о внедрении классического ECM-продукта: толстый клиент, веб-клиент).
А вот еще одно применение нашлось для технологии Compreno - приложение Живые страницы превращает "Войну и мир" Льва Толстого в интерактивное произведение.