Релевантность результата поиска: а судьи кто?

Релевантность результата поиска: а судьи кто?
«Отсортировано по релевантности» говорит мне ежедневно Яндекс, давая тем самым понять, что существует некий великий и ужасный критерий, который позволяет поисковику показать мне, что он может находить то, что, по его мнению, наилучшим образом удовлетворит моим потребностям.
1. Релевантность и пертинентность
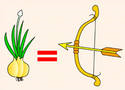
Вообще говоря, релевантность – это степень соответствия результатов поиска введённому поисковому запросу, которая вычисляется по каким-то хитрым формулам, учитывающим частоту употребления слова в просматриваемом тексте, а если слов в поисковом запросе было несколько, то при подсчёте релевантности учитывается ещё и близость искомых слов по отношению друг к другу. Есть подозрение, что при поиске в глобальной сети при вычислении релевантности также учитывается и число посещения сайтов (например, ссылки на Wikipedia всегда находишь первыми или вторыми в списке), и ещё ряд других таинственных критериев. В целом, релевантность – довольно размытое понятие, которое не даёт вообще никакого понятия о том, найду ли я на сайте (в документе) то, что я действительно хотела найти, т.е. является ли результат запроса пертинентным. Пертинентность определяет степень семантического соответствия результатов поиска запросу. Например, я искала рецепт приготовления какого-нибудь блюда из лука и, будучи неопытным пользователем, набрала в строке поиска только слово «лук». С точки зрения системы документ с классификацией видов стрелкового оружия будет абсолютно релевантным запросу, и это верно, но такой результат для пользователя пертинентным являться не будет.
Вынуждена согласиться с тем, что поисковый движок попросту не может самостоятельно оценить пертинентность запроса, поскольку не умеет, как и большинство людей, читать мысли, а ещё его очень легко обмануть. Что же мы имеем в итоге? Поисковики подменяют пертинентность релевантностью, пытаясь таким вот формализованным образом подменить неформализуемое понятие.
2. Отображение релевантности
Поисковые движки разнообразных систем (будь то специализированные сервисы в интернете, или модули прикладных программ) на подмене понятий не останавливаются. Некоторые из них предлагают пользователю посмотреть ещё и числовое значение релевантности, например, в процентах: от 0 до 100, или шкалу релевантности запроса (навроде: у кого релевантнее, у того и шкала длиннее), а иногда и вовсе и то, и другое.

Скажем, ищу я слово «собака», получаю списки сущностей (документов или сайтов), возле ссылки на каждый из которых указано некое числовое значение, скажем, возле ссылки на книгу о породах собак будет стоять значение, близкое к 90%, потому что искомое слово, по всей видимости, очень часто в указанной книжке встречается. Хорошо, я согласна, скорее всего такой запрос будет пертинентным. Однако, что если я создам документ, в котором 500 раз напишу слово «собака» подряд и больше ничего? Удивительно, но такой документ будет самым наирелевантнейшим по запросу «собака». Если алгоритм позволит, то релевантность запроса будет близка к тысяче процентов. О пертинентности промолчу. А ещё я видела результаты поиска, у которых релевантность была нулевой, но в список результатов поиска их всё же пустили. Наверное, из жалости.
Нужны ли мне были эти цифры, пригодились ли они мне хоть раз в жизни? Нет. Сама по себе цифра не даёт вообще никакого понятия о том, что было найдено по запросу. Ну и что, что у одного документа 90%, а у другого 93, мне вообще вот тот был нужен, у которого почему-то 27% указано. Нужна ли мне шкала? Тоже сомнительно. Шкала нужна, чтобы сравнить, опять же, что? Количественные оценки релевантности! Хм… Снова не то. Цифры релевантности нужны только при отладке алгоритма поиска, пользователю их видеть не нужно. Достаточно, на мой взгляд, отсортировать.
3. «А судьи кто?»
Релевантность – хороший способ формализовать оценку похожести документа, найденного поисковым движком, исходному запросу пользователя. Однако, релевантность результата в данный момент даёт большую степень пертинентности только в том случае, если запрос был грамотно (читай «по-машинному») сформулирован (иногда с использованием спецсимволов поискового движка). Пользователь, имеющий представление о том, что система работает в рамках алгоритма, подменяет обычный человеческий язык машинным, но ведь как сказал американский писатель Спайдер Робинсон: «Я как писатель-фантаст уверен, что этот чёртов робот должен говорить на человеческом языке, а не наоборот».
В общем случае пользователь хочет задать запрос на естественном языке (без использования логических операторов и проч.) и получить пертинентный результат. Как мы уже поняли, высокая степень релевантности не всегда подразумевает высокую степень пертинентности. Что же может помочь системе сформировать наиболее пертинентный результат?
Возможно, это поможет сделать история запросов конкретного пользователя. Так, например, для сервера ECM-системы ничего сложного не составляет вести историю запросов и полученных результатов в работе одного и того же пользователя. Этого пользователя при общем подсчёте статистики можно объединить в группу с другими пользователями (например, выполняющими сходные функции делопроизводителя или руководителя).
Таким образом, сильно упрощённый алгоритм работы поискового движка для получения пертинентных результатов может быть следующим:
- Пользователь вводит запрос и получает список результатов, релевантных этому запросу.
- Пользователь просматривает список релевантных результатов и отмечает те из них, что оказались пертинентны запросу. В этот момент устанавливается связка по пертинентности между запросом и отдельным его результатом.
- При последующем вводе того же самого запроса отмеченные значком пертинентности релевантные результаты обладают приоритетом перед результатами, не отмеченными таким значком.
Возникает вопрос: как отмечать результаты, пертинентные запросу? У современных систем есть все возможности для этого: подавляющее большинство поисковиков в интернете при демонстрации результатов поиска всегда предоставляют пользователю фрагмент текста, в котором фигурируют искомые слова (а Googleдаже организует красивый предпросмотр страничек). Так, при некоторых допущениях, можно сказать, что если пользователь перешёл по ссылке, то он счёл результат пертинентным (отмечать галочкой, а ещё хуже заставлять пользователя проставлять процент пертинентности – это пример дьявольского моветона). В конце концов, ведь как-то же организована контекстная реклама и прочие фишки. Запомнить пользователя можно не только по ip, но ещё и привязав его к своему поисковику посредством почтового ящика на том же сервере.
Для ECM-систем всё ещё проще: пользователи в условиях ограниченности базы данных и более медленного её роста (по сравнению с интернетом) обычно знают, что они ищут (документ с известным названием, известного автора, недавно открытый и проч.), из чего следует, что сам факт открытия документа, найденного среди прочих по запросу, практически подтверждает пертинетность результата запросу.
Набрав, таким образом, некую статистику, система сможет с повышенной вероятностью давать пользователю не только математически верный результат (релевантный), но также и семантически соответствующий его запросу (пертинентный).
А судьи – мы.
Похожие статьи


ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 14
Пертине́нтность (лат. pertineo — касаюсь, отношусь) — соответствие найденных информационно-поисковой системой документов информационным потребностям пользователя, независимо от того, как полно и как точно эта информационная потребность выражена в тексте информационного запроса. Иначе говоря, это соотношение объёма полезной информации к общему объёму полученной информации.[1]
↑ 1 2 3 4 Словарь по кибернетике / Под редакцией академика В. С. Михалевича. — 2-е. — Киев: Главная редакция Украинской Советской Энциклопедии имени М. П. Бажана, 1989. — 751 с. — (С48). — 50000 экз. — ISBN 5-88500-008-5Предлагаю не вдаваться глубоко в вопросы релевантности для поисковых систем, так как это отдельная большая тема других сайтов. Но требования к СЭД работать как "большие поисковики" - это конечно реальность. Это одна из причин, почему пользователи предпочитают искать в Интернет (что подтверждает и наш опрос и выводы аналитиков).
Я посмотрела опрос и нашла саму постановку вопроса довольно странной: у поиска в СЭД и поиска в интернете вообще разные цели, сравнивать их друг с другом я считаю некорректным. Статью я тоже посмотрела, но мне показалось, что затронутая тематика её и этого поста резко друг от друга отличаются (в статье затрагивается важность функциональность поиска в СЭД как таковая). Пост же был призван, скорее, затронуть тему, объединяющую и поиск в СЭД, и поиск в интернете: повышение пертинентности результатов (в отличие от релевантности).
уже давно используется в корпоративных средствах поиска, а также еще целая куча инструментов: предпросмотр, аудитории, объединения реультатов поиска по нескольким системам, сложная фильтрация и пр.
Если интересен корпоративный поиск, то советую взглянуть в сторону FAST поиска.
http://sharepoint.microsoft.com/en-us/Pages/Videos.aspx?VideoID=17
Конечно, можно кричать и ругаться, что это MS и все такое ;), только не следует забывать, что FAST - это лучшее hi-end решение для корпоративного поиска на данный момент.
Да, FAST - это интересная технология. Правда, способ аргументации приводит в недоумение:
можно раскрыть подробнее, что именно в этой аргументации привело в недоумение?
Иван, спасибо за ссылку на FAST. Уверен, что даже если кто и не знал о нем, теперь смогут лучше познакомиться с действительно неплохой поисковой разработкой. Думаю, Mi*oft не ошиблась, приобретя FAST пару лет назад, а Docu*tum не ошибся, отказавшись от него.
хм, насчет Documentum не знал.. спасибо большое за ссылку!
Думаю, Mi*oft не ошиблась, приобретя FAST пару лет назад, а Docu*tum не ошибся, отказавшись от него.
Да, я тоже это упустил, но тут похоже (судя по датам новостей на сайте Documentum), это связанные события.
Кстати, было бы интересно посмотреть что на сей счет (рынка Enrterprise Search) думает Gartner, у них даже есть уже готовый отчет Overview for an Enterprise Search or Content Analytics Project 2010, но мое любопытство не стоит $200 :)
Так что подожду каких-нибудь публичных материалов (или комментариев коллег).
забавно.. SP преващается в сверхплатформу: уже PerfomancePoint (да, не весь), Project Server, а теперь еще и FAST.