
Технологии применения видеоаналитики в поисковых системах и проблемы поиска медиаконтента в ECM

Полноценный поиск по медиаконтенту является открытой проблемой как для информационно-поисковых систем, так и в ECM.
Современные ИПС (информационно-поисковые системы) близки к совершенству при работе с текстами и изображениями. Они научились понимать с полуслова, тщательно отбирать полезную информацию и находить содержимое по образцу. Однако, с поиском по видео контенту все гораздо сложнее. Проблема состоит не в том, чтобы научиться находить по текстовому запросу необходимое видео (с этим современные поисковые системы справляются), а в создании универсальной технологии классификации, структурирования и индексации видео, для точной идентификации объектов и событий. Согласно мнению генерального директора и основателя AlchemyAPI Эллиота Тернера, в некоторых отношениях работать с видео даже проще, нежели с изображениями. Там появляется временной контекст, содержащий дополнительные сведения, чего нельзя сказать о фотографиях. Контекст помогает понять системе, что происходит в кадре.
Проблематика
Смоделируем реальную ситуацию. Нам необходимо найти отрывок из видео конференции, где демонстрируется прототип очков Google. У нас в системе десятки видеозаписей с различных конференций, и мы точно не знаем в какой нужно искать. Все что от нас требуется, это передать поисковой системе запрос «очки Google», а в ответ мы получим видеофайл с временной меткой, на которой демонстрируются те самые очки. Для реализации такого поиска, система должна знать, как выглядят абстрактные очки, и понимать где говорится об очках, как о продукте Google. При этом не стоит забывать о том, что видео подвергнуто сжатию и для его воссоздания и обработки требуется много времени и ресурсов.
Выделяется несколько ключевых проблем:
- Видео находится в сжатом виде. Воссоздание и обработка кадров ресурсоёмкий процесс.
- Необходимы универсальные модели объектов реального мира и методы по их идентификации на видео с последующим структурированием информации о них.
И если первая проблема несет в себе сугубо технических характер и её решение не столь интересно, то со второй не все так просто.
Большинство подходов, призванных решить проблему №2, основано на создании технологий автоматического индексирования видеопотока, то есть автоматического заполнения метаданных видеофайлов на основе различных методов и принципов, таких как:
Видеосинопсис. При построении видеосинопсиса из видеопотока создается наиболее общее представление о видео, содержащее все, что было на видео в виде изображения. Это позволяет обрабатывать видео контент как одно изображение.

Визуальные дескрипторы позволяют собрать некоторые характеристики видео, такие как цвета, текстуры, формы, движения, локации.
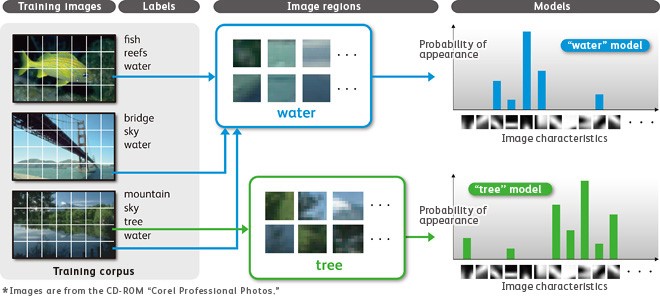
Видеоаналитика в одном из понятий позволяет собирать статистические данные из видео. Розничные торговцы уже начали использовать видеоданные в своём бизнесе. Анализ видео помогает им определить, в каких магазинах сети идёт наиболее оживлённая торговля, где люди задерживаются, чтобы рассмотреть товар, а где проходят мимо. Некоторые даже размещают камеры на уровне глаз, чтобы определить, на каких товарах останавливается взгляд покупателя: это позволяет грамотнее размещать продукцию на стендах. Система распознавания может определить пол, возраст и расу, что помогает проводить таргетированные маркетинговые кампании.
Поиск образов основан на поиске соответствий представлению об искомом объекте на видео.
Распознавание речи позволяет выделить некоторую информацию как из аудиофайла, так и из прилагаемого видео. Это могут быть темы, о которых говорят на видео, различные термины.
Поиск текста позволяет анализировать, к примеру, видео презентации на предмет наличия текста, распознавать его и использовать в качестве метаданных.
Медиаконтент в ECM
С каждым годом роль медиаконтента в ECM растет. Записи презентаций, видеоконференций, рекламные ролики, вебинары – все это являются неотъемлемой частью корпоративных знаний многих организаций. Однако не достаточно просто хранить их – необходимо обеспечить удобную навигацию по ним.
В отличие от поиска по текстовым документам, медиаконтент располагает меньшими начальным возможностями для самоидентификации. В связи с отсутствием аналога полнотекстового поиска, остается единственный вариант – поиск по метаданным. Однако ручное заполнение метаданных требует как времени, так и ответственности за полноту описания мультимедийного документа, так как иначе он может потеряться в обилии остальной информации и утратит свою ценность.
Реализация полноценного поиска по медиаконтенту является открытой проблемой для информационно-поисковых систем. Видится, что такая ИПС, должна состоять из следующих ключевых блоков:
1. Визуальный анализ. Поиск конкретных объектов на основе их хранимых моделей.
2. Распознавание речи (Speech to Text). Создание тестового представления видеофайла.
3. Распознавание текста. Текст со слайдов, заголовков, надписей с плакатов, досок и т.д.
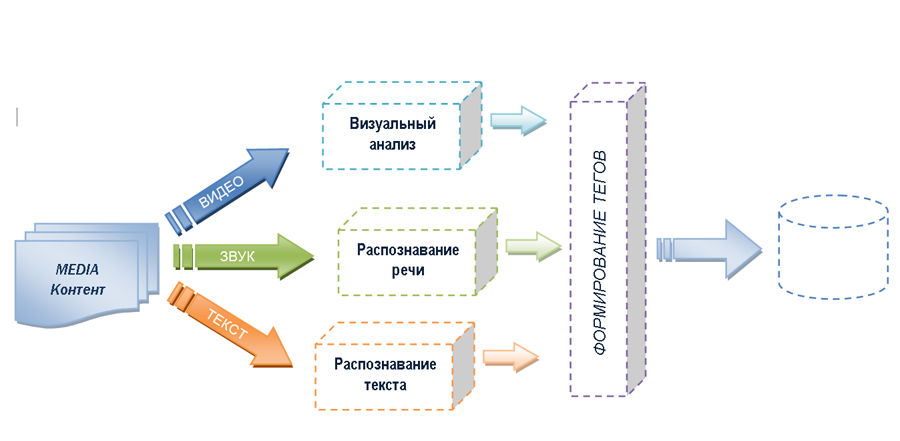
И если задачи из пунктов 2 и 3 в какой-то степени решаются уже существующими технологиями, то решение задачи из пункта 1 остается пока весьма туманным.
Похожие статьи



Комментарии 1