
Open Packaging Conventions #2. Собираем MS Word документ руками
Сегодня мы в качестве практики создадим пару документов для MS Word, не используя никаких специальных инструментов (за исключением XML-редактора и Zip-архиватора).
 В предыдущей статье я постарался “просто и доступно”
В предыдущей статье я постарался “просто и доступно” ![]() рассказать о том, что такое Open Package Convention (или иначе говоря, как устроены изнутри документы MS Office 2007+).
рассказать о том, что такое Open Package Convention (или иначе говоря, как устроены изнутри документы MS Office 2007+).
Сегодня мы в качестве практики создадим пару документов для MS Word, не используя никаких специальных инструментов (за исключением XML-редактора и Zip-архиватора).
Сразу же оговорюсь, что мы не будем сильно вдаваться в особенности разметки документов Word (хотя, конечно же, минимальные представления о ней все же понадобятся, но всё необходимое для понимания я постараюсь рассказать по мере развития статьи)! Наша задача: увидеть как строятся реальные пакеты на основе OPC – что такое компоненты, связи и как они хранятся.
Документ #1 – простой текст
Если попробовать заглянуть внутрь готового Word-документа, созданного в Office, можно легко прийти в ужас от обилия различных компонент непонятного формата назначения.
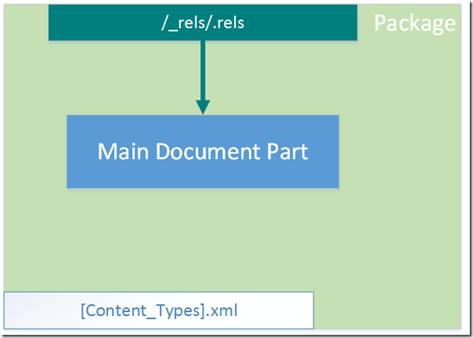
В реальности структура самого простого рабочего документа (такого, который сможет открыть и показать Word) включает всего 3 элемента:
- главный компонент, который содержит разметку всего документа
- 1 компонент связи (который содержит связь между пакетом и главным компонентом
- описание типов (файл [Content_Types].xml)
Примерно так:

Давайте теперь создадим пустую папку, которая будет представлять содержимое всего пакета, и будем последовательно её заполнять.
Главный компонент документа. Создадим в нашей папке файл main.xml (в стандарте OpenXML нет жесткого требования к именованию компонент, поэтому мы будем использовать свои имена, не такие как в Word).
Этот файл будет представлять содержимое главного компонента (Main Document ы терминологии стандарта). В лучших традициях книг по программированию зададим ему следующее содержимое:
<document xmlns="https://schemas.openxmlformats.org/wordprocessingml/2006/main">
<body>
<!--
Структра тела документа включает в себя:
параграф (тэг <p>)
элемент текста с форматированием (тэг <r>)
собственно отображаемый текст (тэг <t>)
-->
<p>
<r>
<t>Hello, World!</t>
</r>
</p>
</body>
</document>
Компонент связи. Теперь мы должны указать что именно компонент /main.xml содержит разметку документа. В OpenXML для этого используется механизм связей. В нашем документе будет только одна связь – от пакета к главному компоненту (главный компонент пока связей не имеет)
Как я писал в предыдущей статье у компонента, который хранит связи всего пакета имя будет /_rels/.rels. Для эмуляции такого имени (чтобы оно потом правильно создалось в конечном ZIP-архиве) мы создадим подпапку _rels, а в ней файл с именем .rels. Содержать этот файл будет всего одну связь:
<Relationships xmlns="https://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="https://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument"
Target="main.xml" />
</Relationships>
Описание типов. По большому счету, в нашем примере используется всего 2 типа контента: в компоненте с основным содержимым документа и в компоненте связи. Однако, хотя мы дали главному компоненту “расширение” .xml, его тип содержимого по стандарту OpenXML должен быть не просто application/xml, поэтому мы опишем 3 типа контента: для всех компонентов связей, для “некого произвольного xml” и явно для компонента /main.xml.
Итак, создадим в нашей папке файл [Content_Types].xml следующего содержания:
<Types xmlns="https://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="rels"
ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml"
ContentType="application/xml"/>
<Override PartName="/main.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>
Итак, содержимое нашей папки составляют 3 файла:
- \_rels\.rels
- \[Content_Types].xml
- \main.xml
Осталось упаковать их в отдельный архив, переименовать архив в, например, result.docx, и открыть полученный файл в Word. Наш результат будет:

Давайте теперь усложним пример, добавив в документ изображение.
Документ #2 – тот же текст и картинка
Какие изменения нам потребуется внести в предыдущий пример? Вот они:
- добавить компонент с изображением и дополнить описание типов содержимого
- создать связь от главного компонента к компоненту с изображением (а это значит, что добавить еще один компонент связей)
- дополнить разметку самого документа (указать место и параметры вставляемой картинки)
Структура нашего пакета приобретет во такой вид:

В принципе, ничего сверхъестественного, поэтому приступим.
Компонент картинки и тип содержимого для него. Для добавления компонента просто скопируем готовый файл с картинкой в папку, к остальным компонентам (пусть это будет файл cat.jpeg).
После этого обновим содержимое файла типов содержимого ([Content_Types].xml):
<Types xmlns="https://schemas.openxmlformats.org/package/2006/content-types">
<Default Extension="jpeg"
ContentType="image/jpeg"/>
<Default Extension="rels"
ContentType="application/vnd.openxmlformats-package.relationships+xml"/>
<Default Extension="xml"
ContentType="application/xml"/>
<Override PartName="/main.xml"
ContentType="application/vnd.openxmlformats-officedocument.wordprocessingml.document.main+xml"/>
</Types>
Связь от /main.xml к /cat.jpeg. Так как мы создаем связь от компонента /main.xml, имя компонента связей для него будет /_rels/main.xml.rels, а значит создадим в папке _rels еще один файл с именем main.xml.rels и содержащем описание 1 связи:
<Relationships xmlns="https://schemas.openxmlformats.org/package/2006/relationships">
<Relationship
Id="rId1"
Type="https://schemas.openxmlformats.org/officeDocument/2006/relationships/image"
Target="cat.jpeg" />
</Relationships>
Осталось самое сложное – поправить разметку самого документа.
Разметка главного компонента. Вообще, надо признать, что разметка документов OpenXML местами весьма далека от “интуитивно понятной” и это справедливо, в том числе для описания изображений (в OpenXML используется единый подъязык для описания любых изображений – DrawingML, у которого есть еще несколько внутренних диалектов: для описания картинок, графиков, …).
Единственный предварительный комментарий нужно дать по поводу размерности единиц… В OpenXML используется специальная придуманная единица EMU (English Metric Unit) – единица, которая позволяет относительно удобно переводить размеры из метрической (метры/сантиметры) и американской (дюймы) систем единиц. Соотношения следующие:
|
1 см |
360000 EMU |
|
1 дюйм |
914400 EMU |
Все, можно оценивать (размеры областей вычислены на основе размеров картинки): Пример.
В нашей папке-пакете теперь содержатся такие файлы:
- \_rels\.rels
- \_rels\main.xml.rels
- \[Content_Types].xml
- \cat.jpeg
- \main.xml
Вновь собираем все в один Zip-архив и открываем в Word:

Вот и все.
P.S. Для желающих продолжить эксперименты – все исходные файлы, а также результаты можно найти на Codeplex в проекте https://msosamples.codeplex.com (здесь и далее я планирую размещать все приводимые примеры). Прямая ссылка на нужную папку.
Источник: Блог Михаила Романова.
Похожие статьи


ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 4
Здорово, Михаил. В нагрузочных тестах генерирую на лету документы похожим способом. Генерирую заявления, акты, отчёты по образцу.
В качестве распаковщика и упаковщика — System.IO.Packaging.Package. В качестве образцов — документы-шаблоны.
Единственное, для скорости, текст документа-шаблона обрабатываю не как XML, а просто как строку, заменяю маркеры в этой строке на необходимый для тестирования текст. И также для скорости, текст "word\document.xml" (в статье это main.xml) извлекаю из документа-шаблона заранее. Чтобы не распаковывать docx-документ каждый раз.
Если записать в одну строку, обновление текста документа-шаблона выглядит так (выделил переменные, которые нужно определить и означить заранее):
package.GetPart(PackUriHelper.CreatePartUri(new Uri(@"word\document.xml", UriKind.Relative))).GetStream().Write(newDocContentBytes, 0, newDocContentBytes.Length);
Привет, Слав.
По поводу API я делал отдельную статью (не знаю, есть ли в планах у редакторов её переопубликовывать на EJ). Впрочем, ты вряд ли там найдешь что-то полезное для себя (там тоже System.IO.Packaging).
А вот о тестировании хочу поговорить подробнее.
Можешь рассказать - что именно ты тестируешь? Т.е. на сколько реально для тебя важен контент документа?
Вообще, по поводу генерации документов я бы сказал следующее: для генерации документов по шаблону внутри предприятия, гораздо более удобным и featured способом является использование Сontent Сontrols (я уже довольно много статей писал по поводу работы с ними, например, из последнего тут и тут).
А по поводу твоего примера кода:
что для тестовых целей такой вариант, скорее всего, более чем достаточен, однако если тебе потребуется использовать его где-то ближе к production, то имей в виду следующее:
using (var mainPartStream = mainPart.GetStream())
{
mainPartStream.SetLength(0);
mainPartStream.Write(newDocContentBytes, 0, newDocContentBytes.Length);
mainPartStream.Close();
}
Ну и конечно, все открытые ресурсы (в первую очередь потоки) нужно обязательно явно закрывать. Не надеясь на финализатор (который не сбрасывает буфера на диск).
Из контента документа важно наличие в тексте уникальных маркеров:
Формально, можно и текстовые файлы отправлять для моих тестовых целей. Текстовые файлы проще формировать и обрабатывать. Но сделал всё как в реальной жизни.
Тестирую сервис межкорпоративного документооборота. Для масштабируемости которого в нём есть ряд асинхронных моментов. В частности, доставка документа получателю.
Проверять в синхронном режиме, кто фактически получит отправленный документ, что будет отражено в регламенте, кто подпишет не хочу. Так как нагрузочное тестирование. Проверяю правильность доставки под нагрузкой, в дополнение к модульным тестам, которые это уже проверили. Именно из-за того, что тут нагрузка: блокировки, ожидания, синхронизации, транзакции и грязное чтение - надо быть уверенным в гарантированной доставке. И проверять не только по именованию, дате, но и по содержимому документов. По содержимому проверяю после завершения нагрузки.
Пробовал вести лог хода нагрузочного теста. Чтобы знать, какой документ когда и кому был отправлен. И потом уже проверять - дошел ли он, что дошел именно он. Механизм логирования становился узким местом. Поэтому выбрал такую стратегию. Каждый тестовый пользователь отправляет документ в котором отражена дата, последовательный порядковый номер, другая информация. И уже потом проверяю, что ни один номер не потерян (это по наименованию проверяю). И оно короткое, в него всё не впишешь. Часть нужной информации извлекаю уже из текста документа.
Тестирование скорости индексирования, скорости полнотекстового поиска становится куда проще, если знать какой контент был в отправленных документах. Тестирование полнотекстового поиска под нагрузкой несовершенно, улучшать и улучшать. И тут нужен контент и лучше, если контент документа офисного формата.
Могу рассказать подробнее, при встрече. Может, сегодня в Удмуртгражданпроект.
За советы по коду, спасибо.
Понял. Да, тебе проще/лучше формировать документы напрямую.
Встретиться увы, пока не получается - в свете последних изменений в семье, я почти не выхожу за пределы круга "дом/работа". Разве что в гости забежишь как-нибудь.