Введение в управление структурированным контентом с помощью XML
Организации, независимо от своей величины, начинают понимать, как за счет контента и многократного использования одних и тех же документов внутри предприятия можно увеличить производительность, а в конечном счете и чистую прибыль.
Кэй Этиер и Скотт Эбел
Организации, независимо от своей величины, начинают понимать, как за счет контента и многократного использования одних и тех же документов внутри предприятия можно увеличить производительность, а в конечном счете и чистую прибыль. Необходимость перемен исходит из желания улучшить управление информационными ресурсами (документами, креативными идеями, изображениями, таблицами, графиками, мультимедиа и пр.) и исключить затратные процессы, которые не способствуют эффективному многократному использованию контента.
Однако самым главным в вопросе управления контентом, подлежащим многократному использованию, является выявление внутренней структуры этих информационных ресурсов. Данную статью можно рассматривать как пособие для начинающих по определению и применению структуры информации в рамках управления контентом.
Аргументы в пользу структуры
Конечно, внедрение структурированного контента, особенно в системах управления веб-сайтами на основе XML, стоит денег. Как уже заметили выше Марк Бейкер и другие, переход к системе управления структурированным контентом может быть довольно сложным, особенно для авторов.
Однако зачастую структурирование является очень выгодным и окупает дополнительные инвестиции. Преимущества:
● упрощается поиск и процедура многократного использования контента;
● снижается стоимость и сложность перевода;
● внедряются нормативы по созданию авторских работ, стилю и брендингу;
● улучшается обмен информацией.
Таким образом, усиление роли структуры при составлении документов может быть довольно полезным, но как это претворить в жизнь? Существует 4 основныхпринципаструктурированияинформации:
1. Определение типов информации.
2. Составление правил иерархии контента.
3. Создание модульного устройства контента.
4. Последовательное применение стандартов.
Рассмотрим каждый из них по очереди.
Определение типов информации
Приступая к анализу существующей документации и будущих требований к ней, необходимо рассматривать контент скорее исходя из типа информации, чем из его формата. Процедуры, предметы обсуждения, фактический материал, постановления, определения, прайсы, номенклатуры и описания продукции – вот наиболее общие типы информации.
Продолжая анализировать создаваемый в организации контент, нетрудно заметить, что многие типы информации можно использовать многократно. Например, нет причин для того, чтобы описание продукции было разным – независимо от того, где оно публикуется. Стоит задать себе вопрос: «Почему мы создаем новый документ, тогда как можно повторно использовать уже имеющийся?». Если ваш бизнес не ставит задачу заново создавать контент, следует рассматривать возможность его многократного использования.
Прекрасным пособием для начинающих в этом вопросе может служить книга «Фундаментальные понятия многократного использования» Анны Рокли, Памелы Костур и Стива Мэнинга(«FundamentalConceptsofReuse», AnnRockley, PamelaKostur, andSteveManning).
Составление правил иерархии контента
Самое главное отличие структурированных документов от неструктурированных заключается в существовании «правил». Эти правила формализуют порядок ввода в документ текста, графических объектов и таблиц. Например, у абзаца неструктурированного документа есть форматирование – шрифт, размер и интервалы. У того же абзаца структурированного документа есть «обертка», которая определяет, какие элементы могут идти в тексте до и после него. Правила оформления элементов задаются в определении типа документа (DTD) или в схеме – далее будет сказано об этом более подробно.
Управление структурированным контентом предполагает уход от меток форматирования и переход к работе с правилами представления информации. Отсюда следует укрепление информационной модели, но при этом возникают сложности с внедрением новой системы управления, так как создатели контента привыкли работать в системах, управляющих внешним видом документа.
Создание модульного устройства контента
Внедрение управления структурированным контентом обязывает рассматривать любой создаваемый документ в виде отдельных, идентифицируемых цепочек информационных блоков, которые можно собирать различным образом в зависимости от аудитории, цели или способа подачи. Отметим, что такой подход носит практический, а не теоретический характер. Чтобы разбить контент на блоки, в каждом конкретном случае нужно ответить на вопрос: как, где и когда вы намереваетесь повторно его использовать.
Однажды определив и описав тегами эти блоки информации, их можно использовать в другой информационной продукции в любой последовательности и с любыми целями.
Ниже показано, как можно использовать модульное содержимое исходного документа при создании рекламного буклета, руководства пользователя и веб-сайта для покупателей.
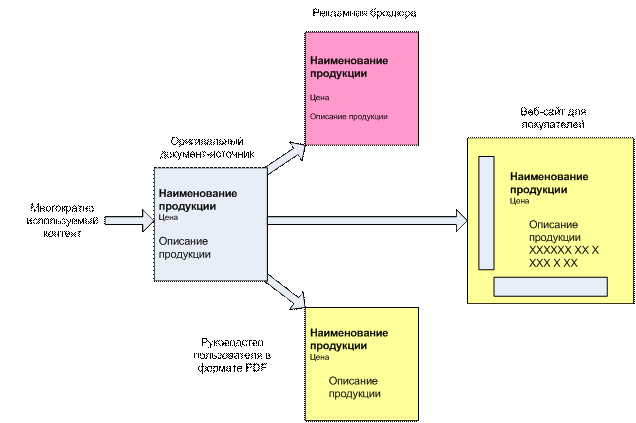
Пример многократного использования блоков контента в компании, торгующей сотовыми телефонами
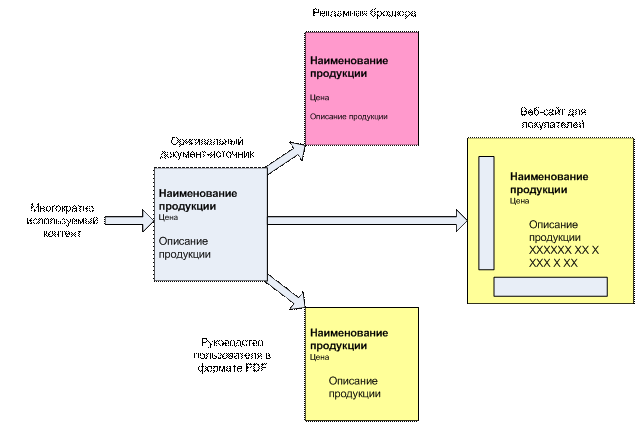
В этом простом примере показано, как компания, торгующая сотовыми телефонами, несколько раз использует блоки информации из исходного документа в рекламном буклете, руководстве пользователя и на веб-сайте для покупателей. Три элемента – наименование продукции, цена и описание продукции – взяты из исходного документа, нет необходимости писать их заново.
Последовательное применение стандартов
Подсознательно мы понимаем важность внутренних стандартов, нормативов по брендингу, формализованной структуры. Но в природе людей заложено снова и снова находить причины для того, чтобы не использовать шаблоны или отклониться от формата «только в этот раз». Нарушение правил недопустимо, когда дело касается создания структурированного контента. Только последовательное структурирование информации позволяет использовать ее многократно. Только представьте, насколько может быть бесполезным телефонный справочник, если работники телефонной компании будут вносить информацию в произвольном порядке. Кто-то использует первую ячейку для внесения имени, кто-то - фамилии. Поиск по такому справочнику может превратиться в кошмар.
Конечно, большая часть контента организации не так жестко структурирована, как информация в телефонном справочнике. Но если стоит цель многократного использования контента, то его структурирование как минимум должно проводиться последовательно. Если кажется, что придерживаться какого-то стандарта по составлению документов слишком сложно, то следует проверить, достаточно ли структурирован ваш контент, или пересмотреть свои ожидания по вопросу возможности многократного использования информации. Можно ослабить рамки шаблонов документов или сделать их более гибкими, но при этом есть вероятность снижения полезности информации.
Блоки построения xml
Итак, вы определили типы контента, поделили их на модули, предназначенные для многократного использования, установили связи между этими модулями, и решили последовательно внедрять эту систему в работе вашего персонала. Работы будет много, но почти всегда этотого стоит.
Теперь нужно немного углубиться в технические детали, касающиеся того, как осуществляется реализация структуры в формате XML, т.е. на языке, специально предназначенном для представления моделей с высокой степенью иерархии (а именно такую вы и создали). Чтобы разобраться, как оперировать со структурированными XML-данными, нужно иметь представление о таких понятиях, как:
● элементы;
● атрибуты;
● DTD-спецификации и схемы.
Элементы
Элемент – это базовая единица информации. Элементами могут являться текстовые фрагменты, графические объекты, таблицы и даже контейнеры для других элементов. Короче говоря, все может быть элементом.
При создании информационной модели определяется иерархия документа. Иерархия задает порядок, в котором можно использовать элементы для определенного информационного продукта.
Например, в нижеприведенной модели комплекта документации для пользователя каждая глава (Chapter) начинается с заголовка (chapterTitle), затем следует краткое содержание (synopsis) и список тем, обсуждаемых в главе. Вот пример XML-разметки, в которой показана структурная иерархия главы.

Элементы являются мощным средством создания структурированного контента, который можно использовать многократно, если только у них есть атрибуты.
Атрибуты
XML-элементы могут включать в себя не только метки, но и другую информацию. У элементов есть атрибуты, т.е. дополнительная информация о каждом элементе. Например, элемент глава (Chapter) дополнительно может иметь атрибут автор (Author) и университет, к которому относится автор (University). Эти атрибуты позволяют найти все работы определенного автора или университета. Далее приведен пример XML-разметки, где показаны атрибуты Author и University.

Имея возможность классифицировать информацию из атрибутов, можно из исходного контента создавать новые информационные продукты.
Авторы документации давно пользуются преимуществами включения атрибутов в элементы формируемого контента, что дает читателям возможность изучать справочные материалы и инструкции с большим пониманием. Атрибуты помогают определить, в каком информационном продукте и на каких языках должен появиться элемент. Например, некоторые элементы следует использовать на веб-сайтах, но они не годятся для печатных справочников; другие должны появиться в испанской, а не португальской версии документа.
Задумайтесь об этом на минуту. Благодаря атрибутам, контент получает возможность саморазвиваться. Например, элементы и атрибуты можно использовать для создания динамического контента для сетевых информационных продуктов, в основе которого лежат личные предпочтения ваших пользователей.
DTD-спецификации и схемы
Структура информационного продукта описывается в определении типа документа (DTD) или в схеме. Схема, в отличие от DTD, представляет собой действительный XML-документ, однако оба способа нашли широкое распространение в описании информационных моделей (DTD-спецификации несколько чаще используются в публикациях, схемы - в разработке), оба имеют большую моделирующую способность и содействуют многократному применению контента.
Проще сначала рассмотреть DTD-спецификации. Ниже показано, как DTD определяет элемент «резюме главы».

Снова отметим, что XML-контент по большей части удобочитаем для человека. В вышеприведенном примере первая строка DTD используется для объявления элемента-главы («Chapter»). Заголовок вводится по желанию («Title?» говорит о том, что заголовка может и не быть), далее следует один или несколько элементов-параграфов (seсtion), при этом «Section», «Section+» говорит о том, что имеется 2 или более параграфа. Следует помнить, что правила задаете вы, DTD – лишь их воплощение.
DTD-спецификации и схемы – как и информационные модели, которые они призваны представлять – могут быть простыми и очень сложными. Если у вас есть интерес к управлению структурированным контентом и многократному использованию информации, то нужно найти время для изучения принципов работы XML и DTD/схем. Информацию можно найти самостоятельно, перечень сетевых ресурсов приведен ниже. Однако, прежде чем приступать к очень сложным проектам, следует обратиться к консультанту, специализирующемуся на создании структурированного контента.
Об авторах
Кэй Этиер – сертифицированный эксперт по AdobeFrameMaker 7.x и некоторым предыдущим версиям. Она ведет подготовительные курсы, занимается консалтингом, обеспечивает поддержку клиентов в различных областях. Проживает в ResearchTrianglePark, Северная Каролина. В 2001 году стала соавтором книги XMLWeekendCrashCourse (Wiley/HungryMinds). Содействовалавсозданиикниг Advanced FrameMaker (TIPS Technical Publishing) и XML and FrameMaker (Apress).
Скотт Эбел - соавтор данной статьи. Является техническим писателем и специалистом по стратегическим вопросам управления контентом. Оказывает помощь организациям в улучшении системы создания, поддержки, публикации и архивирования информационных ресурсов.
Перевод компании DIRECTUM.
Источник: CMS Watch ("Introduction to Structured Content Management with XML")
Похожие статьи



ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 0