Методы контент-анализа сети Интернет: извлечение знаний, а не фактов
Известному американскому контент-аналитику, Джону Найсбиту, принадлежат слова: "Мы тонем в информации, но изголодались по знаниям".
Владимир Шалак
кандидат философских наук, старший научный сотрудник Института философии РАН
Известному американскому контент-аналитику, Джону Найсбиту, принадлежат слова: «Мы тонем в информации, но изголодались по знаниям».
Это он сказал в своих знаменитых «Мегатрендах», и их вполне можно отнести к тому состоянию, в котором находится подавляющее большинство пользователей сети Интернет.
Традиционно считается, что знания добывает наука. Цель ее – увидеть в первоначальном хаосе закономерную связь явлений и тем самым сделать более безопасным и предсказуемым наше будущее. В однородной среде никаких закономерностей быть не может. В физическом мире говорить о закономерностях можно там, где имеется неравномерность распределения вещества или энергии. В обществе закономерные связи наблюдаются там, где имеется неравномерность распределения масс людей, материальных ресурсов, денежных масс. В информационной среде Интернет закономерные связи должны наблюдаться там, где имеется неравномерность распределения информации.
В ответ на запрос к поисковой системе пользователь получает набор фактов: на станице расположенной по такому-то адресу напечатано то-то и то-то и т.д. Это общение с Интернет как просто с гигантским хранилищем фактической информации. Занятие полезное, но не самое интересное.
Отвлечемся немного и представим, что нам в руки попала электронная база данных какой-то больницы. О каждом пациенте, который обратился в эту больницу, известны его жалобы, диагноз, терапия и результат лечения. Если отнестись к этой базе данных просто как к набору фактов, а именно этим она и является, то ничего интересного из нее извлечь нельзя. Но к больничной базе данных можно отнестись и иначе. Если для каждого больного известны его жалобы, диагноз, терапия и результаты, то, обобщив должным образом больных с одинаковыми диагнозами, мы можем выяснить, какая терапия для них оказалась наиболее успешной, приведя к положительным результатам лечения. Мы, таким образом, получим знание, связывающее диагноз с успешной терапией, и в будущем сможем его применить при лечении новых пациентов.
Интернет – это гигантское зеркало. Каждую секунду миллионы людей в самых разных точках земного шара создают свои личные страницы, на которых восхищаются умом своих детей и рассказывают о проведенном летнем отпуске, болтают в чатах, участвуют в работах форумов, обсуждая злободневные темы, оставляют свои комментарии к почитанным газетным статьям, помещают объявления о поиске работы, пишут отчеты о проделанной работе, публикуют аналитические статьи, бумажные и электронные СМИ поддерживают работу своих Интернет-представительств, дублируя журналистские материалы, политические партии сообщают о проведении очередных митингов и пр. и пр. Список можно продолжить. Мораль заключается в том, что Интернет – это живая постоянно меняющаяся мозаика, и его содержание заключается не только в цвете и форме отдельных камешков мозаики, но и в общем рисунке – неравномерности распределения цветов, закономерностях их мерцания. Нет такого секрета, который прямо или опосредованно не нашел бы своего отражения в сети Интернет.
Метод, о котором я хочу рассказать, не требует приобретения каких-то новых программ или подключения к платным сервисам сети Интернет. Все с точностью до наоборот. Ничего, кроме обычных Windows и обычного выхода в Интернет, не нужно. Подойдет даже выход в Интернет через модем и обычный телефон.
Я расскажу вам всего лишь об одном способе искать закономерности в сети Интернет, который реализуется наиболее просто, и который вы сможете начать применять придя домой уже сегодня. Подобных методов разработано нами гораздо больше, но в силу формата доклада и ограничений по времени я не смогу о них рассказать.
Говоря о неравномерности распределения информации в сети Интернет, я пока что никак не уточнил, о какого рода неравномерности будет идти речь. Неравномерность распределения информации относительно чего? В настоящем докладе я собираюсь говорить о неравномерности распределения информации в логическом пространстве и неравномерности относительно оси времени.
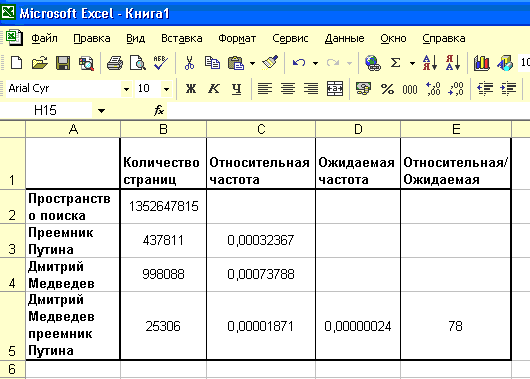
Давайте откроем главную страницу поисковой системы Яндекс. В самом низу ее написано, что поиск ведется по 1352647815 страницам. Запомним это, а лучше занесем в Excel.
Теперь сделаем запрос «Дмитрий & Медведев». Знак конъюнкции между словами запроса означает, что они должны встречаться в одном предложении, а не просто в разных местах страницы. В ответ получим список страниц, на которых упоминается зампред. правительства Дмитрий Медведев. Но нас будет интересовать не этот список, а его количественная оценка – 998088. Ее также занесем в Excel.
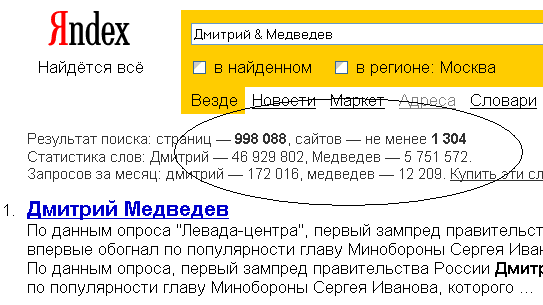
Следующий запрос – «преемник & Путина». Количественная оценка – 437811.

Мы хотим получить ответ на вопрос, есть ли какая-то связь между распределением страниц, удовлетворяющих запросам «Дмитрий Медведев» и «преемник Путина»?
Изобразим полученные оценки на круговой диаграмме. Общее количество страниц, по которым осуществляет поиск Яндекс, назовем универсумом и изобразим кругом, обозначенным буквой U. Страницы, соответствующие запросу «Дмитрий Медведев», представим кругом A, а страницы, соответствующие запросу «преемник Путина» представим кругом B.
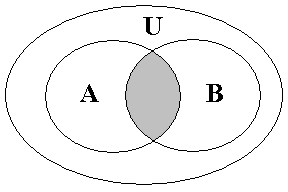
Кругам A, B мы можем сопоставить доли, которые занимают они от всего универсума.
P(A) = 998088/1352647815 = 0,000738
P(B) = 437811/1352647815 = 0,000324
Я не буду вдаваться в детали, но скажу, что в теории вероятностей и в вероятностной логике A и B независимы друг от друга, т.е. никак не связаны, если произведение P(A) на P(B) равно относительной площади их пересечения, которая на нашей диаграмме закрашена в серый цвет.
Чтобы выяснить эту площадь пересечения, зададим Яндексу еще один запрос - «Дмитрий & Медведев & преемник & Путина».

Его количественная оценка – 25306, а доля P(A и B) = 25306/1352647815 = 0,000019
Вычисляем произведение
P(A)*P(B)=0,00000024.
И теперь берем отношение
P(A и B)/P(A)*P(B) = 0,000019/0,00000024 = 78
При независимости наших двух запросов это отношение должно было быть равно примерно 1, мы же получили 78. Это означает, что на реальной диаграмме закрашенная площадь в 78 раз превосходит ту, которая была бы при независимости двух запросов.
Вывод, который можно сделать из этого, очевиден – имеет место очень сильная тенденция связывать имя Дмитрия Медведева с потенциальным преемником Владимира Путина.
Проделайте подобное исследование и для других кандидатов в преемники, и вы получите прекрасный материал для журнальной статьи на злободневную тему. Результирующие оценки позволят сопоставить кандидатам в преемники их рейтинг. Так как Интернет является отражением реальных процессов, происходящих в обществе, больших денег и материальных ресурсов, вложенных в раскрутку кандидатов, то выводы могут быть сделаны самые далеко идущие.
Ниже предоставлен рейтинг кандидатов в преемники, полученный вечером 21 января:
Сергей Собянин 2945
Дмитрий Медведев 78
Серей Иванов 31
Владимир Якунин 16
Сергей Миронов 11
Результат весьма неожиданный, но каждый может его перепроверить.
Я привел довольно упрощенную модель обнаружения логических закономерностей, которая для полной научности должна быть дополнена критериями принятия гипотез и пр. Но и в этом виде она вполне пригодна для получения интересных результатов.
В качестве дальнейших иллюстраций данного метода приведу результат анализа отношения к В.Путину в западном сегменте сети Интернет.
Исследование было проведено с помощью поисковой системы AltaVista с разбивкой по годам с 2000 по 2005.
Для оценки негативного отношения к В. Путину делались три запроса:
● Putin,
● Bad,
● Putin & Bad,
где Bad – это список высокочастотных слов английского языка - (aggressive OR alarm OR bad OR crime OR crisis OR danger OR dislike OR error OR evil OR fail OR fear OR harm OR hostile OR kill OR menace OR mistake OR nonsense OR poverty OR protest OR regret OR suffer OR terror OR threat OR unfair OR unpleasant OR unsuccessful OR useless OR worry OR wrong)
Аналогично для оценки позитивного отношения к В. Путину.
Good = (admire OR agree OR alive OR approve OR award OR dear OR fine OR good OR goodness OR happy OR honest OR humor OR joke OR joy OR lucky OR nice OR peace OR peaceful OR pleasure OR prosperity OR reward OR rich OR sincere OR skillful OR smart OR smile OR success OR successful OR well)
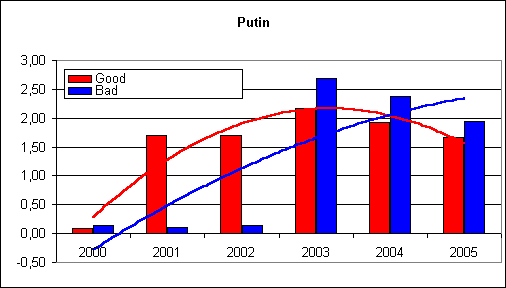
2000 год – к Путину присматриваются.
2001-2002 гг. – положительные публикации в адрес Путина превалируют над отрицательными.
2003 – 2005 гг. - с момента ареста Ходорковского отношение к Путину меняется на негативное.
Я не буду приводить диаграммы и подробно рассказывать о других исследованиях, хотя многие из них оказались весьма интересными и позволили получить нетривиальные результаты. Взять хотя бы исследование о связи войн и цен на нефть.
Обычно все убеждены в том, что войны ведут к повышению цен на нефть и бензин. Это устоявшееся твердое мнение. Оказалось, что оно является ошибочным. Не войны ведут к повышению цен на нефть, а повышение цен на нефть ведет к войнам. Это далеко не тривиальный результат с точки зрения геополитики. Но до сих пор почему-то уверены в обратном, а потому и прогнозы развития политической ситуации в нефтеносных регионах могут быть ошибочными.
В заключение несколько предложений по части практического использования предложенного метода поиска закономерностей.
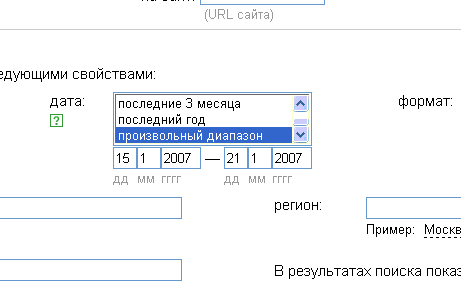
Единица жизненного цикла сети Интернет – это неделя, которая естественным образом связана с нашей обычной рабочей неделей. Если кто-то заинтересуется мониторингом по этому методу, я бы посоветовал делать это каждый понедельник. Яндекс в расширенном поиске позволяет указать временной интервал, который вас интересует. Например, сегодня понедельник 22 января. Прошлая неделя началась 15 января, а закончилась вчера – 21 января. Заходим в расширенный поиск Яндекса и указываем временной интервал 15.1.2007-21.1.2007, затем вводим текст интересующего вас запроса. Эту процедуру повторяем каждый понедельник.
Если делать это регулярно, то вам не нужны будут никакие сводки социологических служб с их опросами. Пользователи сети Интернет уже успели высказать свои мнения по всем вопросам, их нужно только собрать.
И последнее замечание, но очень важное. Обязательно подробно изучите язык запросов поисковой системы, которой собираетесь пользоваться. Дело в том, что, как говорится, каков вопрос – таков ответ. Если вы ошибетесь в правильной формулировке запроса, то сами себя введете в заблуждение, и виноват в этом будет не метод, а только вы. В то же время искусное использование языка запросов позволит вам производить очень тонкое, я бы сказал, хирургическое извлечение тех знаний, которые содержит в себе Интернет.
(Текст выступления
на семинаре в клубе «Билингва» 22 января
Источник: Проект ВААЛ
Похожие статьи



ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 1
Что касается утверждений типа "в однородной среде никаких закономерностей быть не может..." - попадись автор таких высказываний в руки, например, гидродинамикам... Даже косточек бы не осталось! Кому, как не философам, знать, что подобные абсолютные утверждения всегда неверны.