Методы построения рекомендующих систем

Сможем ли мы когда-нибудь шагнуть из Web 2.0 в сторону Enterprise 2.0, большой вопрос, но все же хотелось бы верить в такую возможность.
Концепция ECM, если смотреть на нее широким взглядом, подразумевает обеспечение эффективного доступа к корпоративному контенту. Отечественные системы электронного документооборота зачастую трактуют эту задачу достаточно узко в виде возможности получения доступа к электронным документам.
Однако развитие современного интернета раскрыло гораздо более широкие возможности для управления контентом, нежели чем банальный доступ к документам. Вполне возможно, что будущее систем управления контентом в том, чтобы привнести эти современные наработки на уровень Enterprise. Вопрос лишь в том, чтобы созрело поколение достаточно опытных пользователей и готовых к внедрению соответствующих современных технологий руководителей предприятий и их подразделений.

Возьмите любой современный интернет-ресурс, предусмотрительно снабженный коллаборативными функциями и хорошей поддержкой различных типов содержимого. С удивительной легкостью современные социальные сети позволяют комбинировать текстовое, аудио- и видеосодержимое, снабжать контент комментариями пользователей и расставлять категории для упрощения поиска информации. Потрясающие возможности для организации накопленных знаний открываются при использовании технологии wiki, которая позволяет накапливать информацию, проставлять связи и категории, упрощать обсуждение и поиск информации. Сможем ли мы когда-нибудь шагнуть из Web 2.0 в сторону Enterprise 2.0, большой вопрос, но все же хотелось бы верить в такую возможность.
Проблемы поиска информации
Ну а теперь начнем потихоньку возвращаться с небес на землю. Всякий раз, когда возникает вопрос об эффективном поиске какой-либо информации, на ум приходят два возможных решения:
● организовать информацию так, чтобы по ней можно было искать
● научить систему лучше находить то, что нужно
Оба подхода хороши и имеют свое право на жизнь. Наверняка, многие из вас пытались когда-либо разложить свои файлы по папкам так, чтобы их можно было найти. И конечно, сталкивались при этом со всеми ограничениями иерархической классификации, когда один элемент может относиться к нескольким категориям и его можно положить в несколько папок. Поддержание хорошей структуры папок, которую при этом совместно использовали бы разные люди из одной организации, требует достаточно высокой дисциплины и постоянной модерации. Ну а по мере роста количества категоризируемой информации задача раскладывания ее по всем необходимым папкам может стать практически невыполнимой. Вряд ли Google когда-либо смог бы построить единую таксономию, в которую вписались бы абсолютно все интернет-ресурсы, которые он индексирует. Поэтому в подобных системах мы вообще можем не найти никакого подобия папок, отправной точкой для поиска будут служить строка поиска и ключевые слова. И при этом пользователи все-таки находят необходимую им информацию.
Это продает – значит это работает
Наверняка, вы работали с каким-нибудь интернет-магазином типа Amazon. Для подобных систем электронной коммерции уже классикой жанра стали списки рекомендаций. Когда вы просматриваете страницу какой-либо книги, вы увидите в области рекомендаций список книг, которые также могли бы вас заинтересовать. По своему опыту могу сказать, что подобные списки действительно работают. Я иногда посматриваю книги по интересным для меня темам и не всегда сразу получается хорошо сформировать поисковый запрос. Поэтому когда ты находишь подходящую книгу, а потом тебе советуют какую-либо книгу по смежной тематике, это здорово помогает.

Алгоритмы рекомендующих системы разрабатываются научным сообществом уже много десятилетий. Алгоритмы, используемые в конкретных коммерческих системах, являются, как правило, коммерческой тайной. Однако используемые подходы широко обсуждаются в научных кругах. Я провел небольшое исследование по таким алгоритмам и хотел бы кратко рассказать о ключевых используемых подходах. Обзор будет в первую очередь концептуальный (только взгляд сверху), глубоко в подробности вдаваться я не буду.
Коллаборативные рекомендации
Один из самых распространенных подходов, используемых при разработке рекомендующих систем, заключается в сопоставлении профилей работы пользователей с системой. В процессе работы с системой накапливается определенная информация о совершенных просмотрах страниц, совершенных покупках. Идея заключается в том, что пользователи, которые проявляют интерес к одним и тем же объектам системы, будут с большой вероятностью иметь схожие интересы, а значит для одного пользователя могут представлять интерес объекты системы, с которыми работает другой похожий на него пользователь. Идея такого алгоритма привлекательна тем, что мы не должны предварительно вводить никакую дополнительную информацию о самих объектах системы. Однако реализация подобного алгоритма на реальных данных встречает ряд сложностей. Анализ степени схожести между различными профилями пользователей при большом количестве пользователей и объектов системы является непростой задачей с точки зрения вычислительной сложности. Остаются вопросы, как поступать с новыми пользователями, которые только еще начали работать с системой и по ним еще не накопилось достаточное количество информации. Также не очень понятно, как быть с объектами, которые еще не просматривались никем из пользователей.
Рекомендации на основе содержимого
Совершенно другой подход к построению списков рекомендации используется в алгоритмах рекомендации на основе содержимого. Данные алгоритмы предполагают, что из самого содержимого объектов системы можно построить списки ключевых категорий или ключевых слов и также можно сформировать списки категорий или ключевых слов, которые бы характеризовали отдельных пользователей системы. Преимуществом алгоритма рекомендации на основе содержимого является возможность «холодного старта», то есть нам не нужно обязательно задействовать большое количество пользователей на наших объектов, чтобы система начала ворочаться. Однако задача ключевых слов на основе содержимого документов не является такой уж простой, как это может показаться на первый взгляд. В худшем случае нам придется самим вручную формировать (или хотя бы корректировать) список таких ключевых слов.
Рекомендации на основе знаний
В некоторых случаях предметная область отличается большим количеством проработанных и готовых к использованию знаний о целевых объектах. В качестве примера можно привести покупку компьютера. Магазин обладает достаточно детальной информацией о типах системных блоков, систем охлаждения, жестких дисков, материнских платах и процессорах. Многие критерии могут носить численный характер, либо выбираться из предопределенных списков. Как правило, при этом существуют достаточно высокоуровневые типовые конфигурации, которые можно использовать в качестве отправной точки при совершении покупки (например, игровая станция или компьютер для работы в интернете). Вся вспомогательная информация о цели покупки может быть запрошена у пользователя в диалоговом режиме. При этом данный пользователь может воспользоваться услугами этого магазина один раз за большое количество лет, то есть нет никакой возможности накопить историю его предпочтений. К таким системам также предъявляются дополнительные требования, чтобы помимо предоставления самой рекомендации они давали бы объяснение, почему именно такой выбор предлагается сделать.
Выводы
Алгоритмы рекомендующих систем получили широкое распространение в системах электронной коммерции. Вопрос применения подобных подходов в системах электронного документооборота является спорным. Однако ожидания современных пользователей формируются бурно развивающимся интернетом, где подобные вещи стали восприниматься как само собой разумеющееся. На скриншоте ниже моя попытка встроить список рекомендаций в интерфейс карточки документа в веб-доступе (строго не судите, рисовал в Paint).
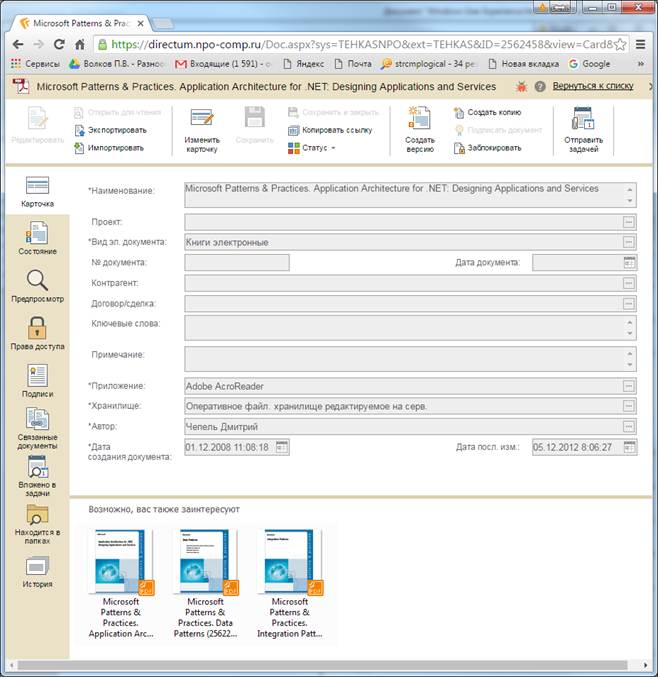
Статья получилась очень обзорной и обобщенной, но именно в таком виде я ее и задумывал. Идеи конкретных наработок и полученных результатов — это тема для обсуждения в комментариях.
Литература
● Jannach D., Markus Z. Recommender Systems: An Introduction
Похожие статьи



ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 4
А что за ограничение?
Например, если мне понадобится классифицировать документы по первой букве автора и по году создания, мне надо будет создавать поддерживать в актуальном состоянии две иерархии.
Ну... да, но
это не баг, это фичаэто же не ограничение, а особенность представления. Приходится чуть больше времени тратить на классификацию. Вот если бы совсем невозможно было сослаться на один документ из двух папок - это было бы ограничение.Интересная статья в тему Как нельзя делать рекомендации контента про методы рекомендаций для СМИ.