
А как строится поиск/классификация в российских ECM-продуктах?

Почему в российских СЭД используются только аттрибутивный и полнотекстовый поиск, тогда как западные системы активно используют тэги и термины?
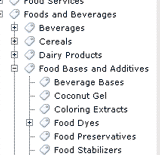 Действительно, намедни я подумал, что из тех российиских ECM-систем, которые я знаю, все поголовно используют (вали) только два типа поиска/классификации — на основании атрибутов документа (как правило, на достаточно жестком наборе) и на основании полнотекстового поиска. Пару раз доводилось видеть использование набора ключевых слов (терминов, тэгов), но как правило, решения были очень упрощенными — на манер ввода тэгов в специальном поле через запятую — ужасное по управляемости и удобству решение.
Действительно, намедни я подумал, что из тех российиских ECM-систем, которые я знаю, все поголовно используют (вали) только два типа поиска/классификации — на основании атрибутов документа (как правило, на достаточно жестком наборе) и на основании полнотекстового поиска. Пару раз доводилось видеть использование набора ключевых слов (терминов, тэгов), но как правило, решения были очень упрощенными — на манер ввода тэгов в специальном поле через запятую — ужасное по управляемости и удобству решение.
Может быть такие системы и есть, просто я с ними не сталкивался (или сталкивался, но с очень ранними версиями)?
А собственно поводом задуматься над этим вопросом меня заставила заметка в блоге Блог команды Microsoft SharePoint: Таксономия — проблема начала с самого нуля (на качество перевода особо не обращайте внимание, но если будет уж очень резать глаз и слух, то можно прочесть исходную публикацию Taxonomy — The Challenge of Starting from Scratch). В этой заметке упоминается компания WAND (или можно сразу заглянуть на сайт их продукта DataFacet), которая поставляет готовые (т.е. уже сгруппированные с готовыми связями между синонимами, с поддержкой нескольких языков, …) наборы терминов для развертывания собственных систем таксономии — чтобы полнее оценить масштаб проделаной работы можно взглянуть на документ (что-то около 250 предметных областей, более 80 тыс. терминов — 40 тыс. основных и примерно столько же синонимов).
Работа большая, кропотливая и, надо полагать, не дешёвая. Однако, спрос на такого рода продукцию, по всей видимости есть — т. к. компания существует уже около 6 лет и вроде бы пока не собирается прекращать свою деятельность. Т.е. пусть и несколько натянуто, но я делаю вывод что в других странах таксономии уже стали достаточно распространенным явлением.
А что у нас?
Вообще, мне как человеку не привыкшему использовать в своей повседневной работе системы тэгов (не считая сайтов и блогов — но на многих из них эта система сделана крайне неудобно) сложно представить на сколько это полезно и удобно. Поэтому о том, что тэгирование в корпоративных системах как минимум не бесполезно, я сужу хотябы по двум моментам:
- системы свободной/не иерархической классификации (по сути тэги) упоминаются в стандарте MoReq
- компания Microsoft потратила очень приличные средства на разработку механизма таксономий сначала в Content Management Server, а затем на перенос и дальнейшее его развитие в SharePoint 2010 (интересная заметка на эту тему Introducing Enterprise Metadata Management).
А каков ваш опыт/мнение?
Похожие статьи


ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 9
Классифицировать архив документов с нуля можно. А вот содержимое существующего большого архива раскидать по крупной таксономии - долго.
Например, если тегов 100, то документов 100 000, к каждому документу 3-4 тега и вот уже 350 000 действий (в среднем) надо совершить. По опыту раскидывания по тегам документов, который был получен при разборе огромной папки документации, оставленной тобой, Михаил, могу сказать, что на один документ может уйти минут 5, а то и 15. Значит ручной вариант надо оставить на потом.
В качестве варианта автоматизации видится автоматическая классификация, когда система знает, что вот этот "список ключевых слов" соотвествует этому "тегу". А далее притягивает в этому тегу все, что содержит в себе нужные слова.
И сделать это можно.
Например, используем списки синонимов (из WordNet), словари англорусские и наоборот, также специализированные справочники (по предметным областям). Ну или покупаем у сторонней компании готовую таксономию по нужной теме и на нужном языке.
WordNet хоть и считается мировым проектом, все слова там на английском (разработчик - Принстон). Кажется, где-то в Новосибирске (университетский проект) создают российкую версию (или переводят английкий вариант или, возможно, пишут свой), но их разработка закрыта. На сколько я помню, для ознакомления с результатами проделанной работы надо позвонить, написать, ... а просто так скачать и ознакомиться пока нельзя. Думаю, если обратьится к ним за готовой таксономией, то они её за разумную цену её предложат.
Бесплатных тематических словарей как толковых, так и русскоанглийких и наоборот в сети много. Во всяком случае состав словарей для StarDict просто огромен, а есть ещё более новые и полные словари у Abby Lingvo.
Из всех этих источников можно сформировать нужный список связок "тег" - "список ключевых слов". И можно следать это в виде xml-файла. А передав xml-файл несложной структуры службе индексации SQL Server (есть там такая возможность), в котором отражена связь синонимов, получим, что при полнотекстовм поиске слова "ЭДО" будут возвращаться все объекты содержащие слова "документооборот" словосочетания "электронный ДО" и наоборот. После чего можно попробовать автоматически проклассифицировать все объекты системы, выполнив столько полнотекстовых запросов, сколько есть объектов (тегов) в таксономии.
По поводу таксономий (как WordNet или таксономия библиотеки конгресса США) - они универсальные, а не предметные (предметных я не видел). Результат от их применения будет, но он будет не идеален. Так как может оказаться, что "стекло" связано с "керамикой", является подмножеством "глины", является подмножеством "песка", "пыли", ... (как-то так было в самой первой версии онтологии из библиотеки конгресса США, когда я её смотрел, см. http://id.loc.gov/download/). И если человек будет искать что-либо про "песок", то в результаты попадёт и "стекло" и "керамика". Универсальная база знаний Cyc, показалось мне очень сложной (сужу по проекту OpenCyc) и я её не осилил. Еще можно извлечь списки "категория" - "объекты" из wikipedia, бекапы которой доступны всем. Даже есть инструментарий для извлечения структурированной части (всё кроме текста) из wikipedia, и уже извлеченная структурированная часть также доступна в готовом виде (см. http://dbpedia.org), но это для английкого и немецкого, для русского языка надо будет извлекать самому.
Есть открытые предметные онтологии для медицины (например Snomed), биологии, химии. Они интересны, подробны и точны. Если планируется классификация документов в EСM для предметной области близкой к медицине или химии - то тут уже есть наработки.
Среди российких разработок по этой теме встречаются инструменты для составления таких таксономий, инструменты для анализа текстов, ... а вот самих таксономий пока не видел.
Как обычно, комментарии ценнее и интереснее исходной статьи.
Спасибо, Слава, более половины из того, что ты перечислил мне был просто не известно!
На мой взгляд, чтобы теги были полезны не отдельному пользователю, а, как минимум, группе, нужно проводить сложную и трудоемкую работу по созданию согласованной системы тегов и её актуализации, а также по соответствующему обучению заинтересованных сотрудников. На своем блоге я стараюсь тегировать материалы, и теги мне нередко помогают быстро отыскать нужную заметку, - но я вижу по статистике, что мои читатели ими не пользуются. И даже для себя сформировать удобную систему тегов оказывается довольно трудным делом!
По мне, так теги до боли напоминают тематические библиотечные картотеки (и аппарат ключевых слов), которые всегда были кому-то полезны, но никогда не были популярным инструментом у основной массы исследователей – в первую очередь потому, что очень сильно отражали специфическую точку зрения составителя картотеки.
Безусловно. Поэтому, готовые наборы терминов если и не решают всех проблем, то как минимум могут серьезно облегчить первоначальные шаги при внедерении.
На сколько мне приходилось сталкиваться, обычно классификационные схемы составляют так, чтобы отнести объект только к одной категории. Тэги же позволяют задавать сразу несколько признаков.
Ничего не могу сказать, т.к. нет реального опыта.
Просто те же Web-ресурсы используют тэги за неимением лучшего и их ведет 1 человек. А что будет когда систему тэгов придется вести централизовано - это вопрос для меня.
Если классифицировать книги, то можно строить классификацию на основе содержимого предметного указателя. Если такой указатель заранее составлен, то это облегчает дальнейший поиск (надо только вынести этот указатель в метаданные).
Тут решается проблема со словоформами при полнотекстовоим поиске - полнотекстовый поиск может не найти нужное слово, если у него другая словоформа. В предметном указателе, как правило, разброса по словоформам нет. Плохо, что такой указатель не во всех книжках/документах есть.
А уже потом строить из совокупного содержимого предметных указателей всех книг/документов нужную тематическую таксономию. Это тоже самое, что и использование тегов, с одним отличием - тегов обычно 3-5 и их формирует читатель, а в предметном указателе гораздо больше элементов и их формирует автор.
О проблемах классификации я писала в посте "Почему мне не нравится такой документ- номенклатура дел"
Там как раз говорилось, почему нужно документ определять в несколько папок одновременно