Эволюция систем, насыщенных данными
В этой заметке не описываются какие-либо новые идеи, она посвящена очень практической теме – проблеме эволюции того, что мы всегда называли приложением базы данных.
Авторы: Энтони Клив,
Том Менс, Жан-Люк Эно
Перевод: Сергей Кузнецов
Оригинал: Anthony Cleve, Tom Mens, Jean-Luc Hainaut. Data-Intensive System Evolution. IEEE Computer, V. 43, No 8, August 2010 pp. 110-112
Reuse Rights and Reprint Permissions: Educational or personal use of this material is permitted without fee, provided such use: 1) is not made for profit; 2) includes this notice and a full citation to the original work on the first page of the copy; and 3) does not imply IEEE endorsement of any third-party products or services.
От переводчика: просто о не слишком сложном
Эту небольшую заметку из августовского выпуска журнала Computer я перевел в основном для развлечения. Люблю читать и переводить статьи, в которых встречаются незаезженные мысли (в особенности, если они созвучны моим собственным мыслям). Так вот, в этой заметке не описываются какие-либо новые идеи, и она посвящена очень практической теме – проблеме эволюции того, что мы всегда называли приложением базы данных.
И особенно для меня приятно, что эта заметка написана в «рабоче-крестьянской» манере, без каких-либо умствований с примененем термина model-driven development и иже с ним (хотя речь, по существу, идет именно об этом). Мне показалось, что эту заметку с удовольствием почитает куча отечественных практиков приложений баз данных, и что она может навести на, возможно, интересные мысли студентов и аспирантов, ищущих темы для самостоятельных исследований. Надеюсь, что не ошибся.
Сегодняшние бизнес-системы обычно являются крупными программными системами, поддерживающими производственные и управленческие процессы соответствующих организаций. Функциональные требования определяют природу бизнес-процессов (например, в терминах их целей), а нефункциональные требования накаладывают ограничения на то, как эти процессы должны поддерживаться (в терминах эксплуатационной надежности, производительности, безопасности, удобства обслуживания и технологической платформы). Выявление изменений требований, их трансляция в изменения системы, применение изменений и развертывание измененной системы в совокупности называются эволюцией системы.
Бизнес-системы подвергаются непрерывной модификации из-за изменений среды, в которой они функционируют. Проблемы эволюции систем пытаются решать исследовательские сообщества и программной инженерии, и инженерии баз данных. Однако, как ни странно, представители этих сообществ проводят очень мало исследований в области пересечения своих дисциплин, там, где программное обеспечение сталкивается с данными.
В большинстве случаев бизнес-система образуется из программной системы и системы данных, которые должны эволюцинировать совместно. Программная система структурируется как набор программ, реализующих бизнес-логику, что достигается на основе интенсивного взаимодействия с системой данных, содержащей бизнес-объекты (заказчики, счета, поставки), которые формируют точный образ бизнеса. Эти бизнес-данные сохраняются в базе данных, обычно управляемой системой управления базами данных (СУБД), и структурируются в соответствии со схемой, точно моделирующей структуру бизнеса и его правила. Каждая таблица данных представляет текущее состояние популяции некоторого бизнес-объекта, его свойства и связи с другими объектами. Любая программа, взаимодействующая с базой данных, организуется в соответствии с частью схемы базы данных, которая направляет ее выполнение, и отсюда происходит термин система, насыщенная данными (data-intensive system).
Функциональная эволюция систем
Если иметь в виду системы данных, то функциональные требования выражаются технологически-независимым образом посредством концептуальной схемы базы данных, содержащей типы сущностей, атрибуты и типы связей. Эта схема затем транслируется в физическую схему, которая отвечает некоторым нефункциональным требованиям, таким как целевая технология баз данных. Наконец, эта схема кодируется с использованием языка определения данных (data definition language, DDL) соответствующей СУБД.
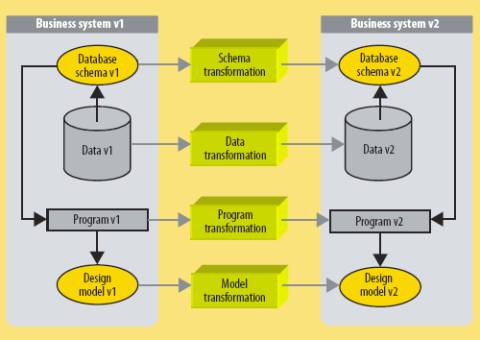
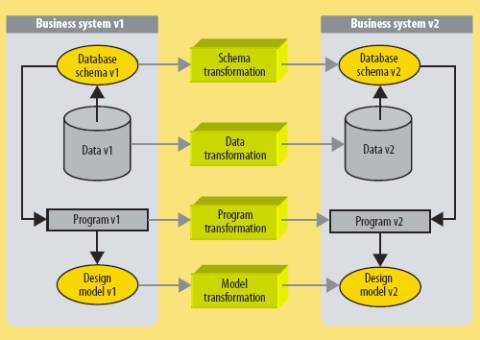
Рис. 1. Эволюция
системы, насыщенной данными.
Этот процесс включает взаимосвязанное преобразование схемы, данных, программ и
проектных моделей.
Как показывает рис. 1, любое изменение функциональных
бизнес-требований приводит к необходимости синхронной модификации четырех
компонентов: схемы базы данных, содержимого базы данных, программ,
взаимодействующих с этой базой данных и проектных моделей, которым должны
соответствовать модели. Например, если нам потребуется разделить ранее слитые
бизнес-объекты «счет» («invoice»)
и «поставка» («shipment»),
то соответствующую таблицу данных INVOICE
будет необходимо расщепить на две новых таблицы INVOICE и SHIPMENT, ее содержимое придется
перераспределить по новым таблицам, и нужно будет поменять операторы доступа к
данным в программах, чтобы они были согласованы с новой схемой базы данных.
В идеальном мире функциональные изменения транслируются в изменения спецификаций – в частности, проектных моделей и концептуальной схемы базы данных. Мы удаляем объекты схемы, добавляем новые объекты и модифицируем некоторые существующие объекты. Эти операции распространяются на физическую схему, в которой соответствующим образом удаляются, создаются и модифицируются таблицы, столбцы и ключи. Поскольку это изменяет семантику данных, последующие операции преобразования данных и изменения программ нельзя полностью автоматизировать, это возможно разве что при весьма незначительных модификациях.
Нефункциональная эволюция систем
Изменения нефункциональных требований обычно приводят к существенному рефакторингу физической схемы базы данных с сохранением поведения программ и семантики данных, выраженных посредством концептуальной схемы базы данных. При выполнении одного из наиболее сложных инженерных процессов – процесса миграции мы должны преобразовать исходную базу данных в целевую базу данных, соответствующую модели данных новой СУБД. Миграция бизнес-системы из среды набора файлов или унаследованной СУБД в среду современной реляционной СУБД была и остается одним из наиболее часто встречающихся процессов преобразования бизнеса. Тщательность выполнения этого преобразования определяет качество результирующей базы данных.
Среди разнообразных сценариев миграции наиболее простым и популярным является физический метод. Он состоит в систематическом преобразовании каждой физической конструкции исходной схемы в наиболее близкую по типу физическую конструкцию целевой модели данных (семантика конструкций при этом не учитывается). Например, при преобразовании набора файлов в реляционную базу данных, следовало бы преобразовать каждый файл в некоторую таблицу, каждое поле данных верхнего уровня – в столбец, и каждый ключ записи – в первичный ключ. Это взаимно-однозначное отображение между исходной и целевой схемами базы данных в большинстве случаев делает преобразование данных и программ достаточно простым.
К сожалению, этот быстрый и недорогой метод слишком часто приводит к плохим результатам. Целевая реляционная схема является неполной, поскольку не включает, помимо прочего, внешних ключей и полей более низкого уровня. Кроме того, она ненормализована и избыточна, не наглядна, не документирована, а поэтому ее трудно использовать и практически невозможно поддерживать и модифицировать. Вдобавок к этому, неприемлемыми могут оказаться показатели производительности.
Более сложный метод семантической миграции приводит к целевым схемам, полностью соответствующим современным стандартам качества и производительности. Он состоит в трансляции концептуальной схемы исходной базы данных в целевую физическую модель. В этом случае отображение «источник-цель» может быть гораздо более сложным: один тип записи может быть распределен по нескольким таблицам, или несколько типов записи могут быть слиты в одну таблицу. Более сложен и процесс преобразования данных, но если мы можем положиться на точность описания отображения схем, то параметры для процессоров извлечения-преобразования-загрузки (Extract-Transform-Load) могут генерироваться автоматически.
До последнего времени проблема автоматического преобразования программ в контексте семантической миграции считалась неразрешимой, но теперь появляются новые фреймворки, основанные на синхронной трансформации схем и программ. Если использовать виртуальную машину, симулирующую API исходной СУБД поверх целевой базы данных, то для этого потребуется минимальная модификация программ.
Потребность в обратной инженерии баз данных
Как функциональная, так и нефункциональная эволюция систем опирается на доступность актуальных концептуальных схем баз данных. Однако на практике такие схемы могут быть неполными, ненадежными, устаревшими или просто отсутствующими. В таких случаях концептуальную схему необходимо воссоздать, по крайней мере, частично.
Достаточно часто схема базы данных известна только из кода DDL или, что то же самое, из таблиц-каталогов базы данных. Этот код обычно является неполным, поскольку в большинстве баз данных многие структуры данных и ограничения не кодируются на DDL из-за недостаточных выразительных возможностей модели данных СУБД или из-за использования проприетарных приемов программирования. Для восстановления этих неявных конструкций требуется дополнительная обработка, такая как статический или динамический анализ программ и интеллектуальный анализ данных (data mining).
Схема, извлеченная из кода DDL и обогащенная неявными конструкциями, которые были восстановлены указанным образом, образуют полную физическую схему. Следующий шаг состоит в извлечении из этой схемы семантики – т.е. в воссоздании концептуальной схемы базы данных. Обратная инженерия баз данных – это сложный процесс, который невозможно полностью автоматизировать, но он обеспечивает разработчиков полной и актуальной документацией старой базы данных, являющейся необходимой потребностью любого процесса эволюции.
Понимание программ для понимания баз данных
Системы, насыщенные данными, демонстрируют интересное свойство симметрии из-за наличия интенсивного взаимодействия базы данных и программного обеспечения, работающего с ее содержимым. При отсутствии какой-либо полезной документации для понимания логики программы необходимо понимать схему базы данных, и наоборот, понимание того, что делает с данными программа, существенно помогает понять свойства базы данных.
Анализ программ является сложным, но насыщенным источником информации, требуемой для воссоздания документации о схемах баз данных. Например, выявление и анализ разделов кода, отвечающих за валидацию данных до их сохранения в файле, позволяют разработчикам обнаружить важные конструкции, поддерживающие, например, декомпозицию реальных записей, ограничения уникальности или ссылочную целостность. И наоборот, такие процессы, как осмысление программ (program understanding), оценка качества и тестирование, выигрывают от хорошего понимания используемой базы данных – в частности, неявных конструкций ее схемы.
Текущие проблемы
Сообщества инженерии программного обеспечения и баз данных все еще испытывают многочисленные трудности, препятствующие должному решению проблем систем, насыщенных данными. Рассмотрим четыре представительных примера таких трудностей.
Большая интеграция средств автоматизации процесса эволюции
В сообществах инженерии программного обеспечения и баз данных независимо разработаны средства автоматической поддержки процессов эволюции. Более высокий уровень интеграции инструментальных средств, разработанных обоими сообществами, сделает системы, насыщенные данными, в большей степени способными к эволюции, и позволить снизить уровень рисков и расходов.
Поддержка функциональной эволюции
Автоматизированная совместная эволюция баз данных и программ оказалась в большой степени оправданной в случае нефункциональной эволюции баз данных, такой как миграция. Обеспечение улучшенных методов поддержки модификации программ в контексте функциональной эволюции является более сложной задачей, поскольку для этого требуется глубокое понимание как логики программного обеспечения, так и семантики данных.
Возрастающее использование динамического SQL
В стандартных подходах к обратной инженерии баз данных интенсивно используются методы статического анализа программ, которые равным образом применимы к жестко заданному статическому SQL. Однако многие современные системы разрабатываются с использованием динамического SQL. В этом случае операторы SQL образуются во время выполнения программы и посылаются серверу баз данных на основе специальных API, таких как Open Database Connectivity (ODBC) или Java Database Connectivity (JDBC). В таких программах статический анализ часто оказывается мало полезным, что вынуждает разработчиков прибегать к применению методов динамического анализа программ для перехвата точного вида операторов SQL и лучшего понимания логики программы.
Разработка программ на основе ORM
В системах, насыщенных данными, прикладные программы взаимодействуют с базами данных через внешнее представление данных. Все более популярное промежуточное программное обеспечение объектно-реляционного отображения (object-relational mapping, ORM) позволяет программистам использовать внешнюю объектно-ориентированную схему базы данных, что снижает уровень воздействия проблемы потери соответствия (impedance mismatch) между моделями программирования и базы данных. Однако в действительности эта технология только ухудшает ситуацию, поскольку теперь физическая и внешняя схемы могут эволюционировать асинхронно, с разной скоростью, и отвечают за это независимые группы. В результате наличия недисциплинированных процессов эволюции между компонентами системы могут постепенно образоваться серьезные несоответствия.
Мы обозначили несколько существенных трудностей, которые необходимо преодолеть, чтобы справиться с проблемой эволюции существующих и будущих систем, насыщенных данными. Преодоление этих трудностей принципиально важно для достижения соответствия предписанным стандартам качества, но для этого требуется значительно более тесное взаимодействие сообществ инженерии программного обеспечения и баз данных.
Источник: CIT Forum
Похожие статьи

ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 0