
Интеллектуальные заблуждения, или Честно про ИИ в российских компаниях

Что же такое искусственный интеллект сейчас, с какими проблемами и маркетинговыми уловками сталкиваются заказчики при внедрении таких инструментов?
По оценкам Frost & Sullivan, мировой рынок искусственного интеллекта (ИИ) растёт ежегодно на 30 %. Появляются новые технологии, позволяющие решать всё больше бизнес-задач без участия человека или с его минимальным привлечением. Обработка и занесение документов, сравнение их версий, определение исполнителей в рамках процессов и многие другие функции уже сейчас доступны пользователям бизнес-приложений с ИИ.
Но что же такое искусственный интеллект сейчас, с какими проблемами и маркетинговыми уловками сталкиваются заказчики при внедрении таких инструментов?

Согласно определению Минэкономразвития РФ, под искусственным интеллектом в России понимается «комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая самообучение и поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые как минимум с результатами интеллектуальной деятельности человека».
На Западе нет единого «узаконенного» определения искусственного интеллекта, однако схожее с приведённым выше есть в Британской энциклопедии: «Artificial intelligence (AI), the ability of a digital computer or computer-controlled robot to perform tasks commonly associated with intelligent beings. The term is frequently applied to the project of developing systems endowed with the intellectual processes characteristic of humans, such as the ability to reason, discover meaning, generalize, or learn from past experience».
Российское и западное определения объединяет несколько постулатов:
- повторение когнитивных функций человека;
- самообучение;
- способность решать задачи и получать конечный результат.
Теперь давайте разберёмся, какие технологии относят разработчики программного обеспечения к ИИ:
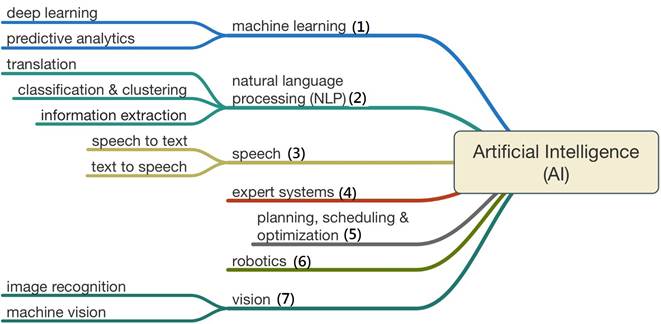
- Машинное обучение (machine learning).
- Обработка естественного языка (natural language processing).
- Обработка речи (speech).
- Экспертные системы (системы принятия решений, expert systems).
- Решение задач оптимизации (planning, scheduling & optimization).
- Роботы (robotics).
- Обработка изображений (vision).
Как видим, нельзя однозначно соотнести существующие технологии и ожидаемое поведение систем с искусственным интеллектом. Из-за этого расхождения у бизнеса часто формируются ошибочные или ложные ожидания от внедряемых систем, а вендоры пытаются подать простые алгоритмы решения задач как интеллектуальные технологии. Но так ли это плохо? Рассмотрим на примерах.
OCR как распознавание документов
Часто инструменты распознавания документов приравнивают к технологии OCR (optical character recognition). Давайте разберём, насколько данное утверждение соответствует фактическому положению дел.
Если рассматривать распознавание документов как бизнес-кейс, то потребность заказчика заключается в том, чтобы из бумажного, электронного неформализованного документа или скан-копии были автоматически извлечены определённые данные (реквизиты), которые нужны для дальнейшей работы в используемой информационной системе. Это необходимо, чтобы упростить занесение документа в систему и сократить временные затраты на выполнение операции.
Из каких этапов состоит этот процесс?
В первую очередь нужно определить символы и слова в документе, извлечь текстовый слой. Именно на данном этапе работает OCR. С её помощью мы получаем список символов, из которых состоит документ. И благодаря технологии – например, рекуррентных нейронных сетей – этот набор символов преобразуется в слова, предложения и абзацы текста за счёт определения расстояния между символами в документе.
Можно ли уже на данном этапе получить нужные реквизиты и заполнить их? Можно. Если пользователь вручную в тексте выделит нужные ему реквизиты и занесет их в соответствующее поле. Оптимален ли такой поход с точки зрения временных усилий? Вряд ли.
Карточки, создаваемые для работы с документами в информационных системах, обычно зависят от характера документа: для входящих писем набор полей один, а для первичных учётных документов — совсем другой. Если система возвращает только текст документа, то пользователь должен сначала вручную указать вид документа для формирования нужного набора полей и затем уже вручную перенести в них значения из текста.
Если говорить про входящее письмо, то кейс выглядит вполне рабочим. Но давайте представим, что речь идёт про счёт-фактуру или УПД. Полей становится значительно больше – появляется табличная часть с перечнем номенклатуры, которую также нужно заполнить. Простая задача превратилась в рутину, равносильную ручному вводу данных с бумажного документа.
Чего не хватает в данном кейсе для приведения задачи к более «универсальному» виду? Прежде всего, автоматического определения вида документа или классификации, которая может быть выполнена как по тексту документа – с помощью технологии машинного обучения, так и по изображению документа – с использованием нейросетей.
Следующий важный этап заключается в определении в полученном тексте необходимых реквизитов, ведь после распознавания текст никак не размечен. Для выполнения этого этапа применяется обработка естественного языка, например, правила, написанные с помощью технологии Томита-парсер от Яндекса или более сложные и точные модели извлечения фактов, реализованные с помощью машинного обучения.
Именно использование в комплексе всех описанных выше механизмов позволяет решить задачу бизнеса: автоматически создать и заполнить карточку с данными документа в системе заказчика.
Для обучения ИИ достаточно 10 документов
«Зачем вам 100 документов для обучения, если они все одинаковые?» – распространённая фраза, которую мы в Directum слышим от заказчиков, когда рассказываем про процесс обучения интеллектуальных сервисов. Действительно ли нужны все эти документы? Или мы просто прописываем отдельные модели для каждого увиденного варианта?
Исторически в России есть требования к оформлению официальных документов. Например, ГОСТ Р 6.30-2003 «Унифицированные системы документации. Унифицированная система организационно-распорядительной документации. Требования к оформлению документов» или Постановление Правительства РФ № 1137 от 26.12.2011 «О формах и правилах заполнения (ведения) документов, применяемых при расчётах по налогу на добавленную стоимость». Эти требования только описывают обязательные для документов реквизиты, но не предписывают использовать для них единую форму.
|
Содержание многих документов вообще не регламентируется законодательством. Всё это ведет к тому, что все контрагенты создают документы по-разному – по тем формам, которые заведены в их информационных системах как шаблоны и печатные формы. |
Для извлечения требований из формализованных документов, таких как УПД, счета-фактуры, товарные-накладные можно использовать накладываемые «поверх» документа шаблоны, так как они действительно достаточно сильно похожи.
Однако на практике, анализируя предоставленные заказчиками документы, мы видим, насколько они отличаются, а неформализованные документы, такие как акты выполненных работ или входящие письма и договоры, изначально требуют иного подхода. Подход этот должен, с одной стороны, учитывать вариативность формы документов, а с другой – использовать единство реквизитов в рамках одного вида документа, чтобы достичь максимальной полноты извлечения.
В реализации такого подхода хорошо показали себя механизмы машинного обучения, которые при формировании моделей учитывают возможные отклонения от идеальной модели и позволяют обеспечить достаточную гибкость в процессе распознавания реквизитов документов.
|
Причём модель может быть обучена и на 10 документах, вот только какие показатели она будет иметь и достаточно ли её для ежедневной обработки большого числа документов? Как показывает практика – нет. |
Такой модели достаточно для апробации в тепличных лабораторных условиях, но не в промышленном контуре заказчика. Именно поэтому чем больше документов будет предоставлено на старте проекта, тем качественнее будет запуск системы в промышленную эксплуатацию. При этом не стоит забывать, что интеллектуальные сервисы регулярно дообучаются и способны учитывать исправления, внесённые пользователем для корректировки существующих моделей.
ИИ должен быть дешёвым
Как мы уже поняли, на рынке интеллектуальных решений нет и не может быть единых стандартов. Даже одинаковые задачи можно решать совершенно разными методами и при этом найти своего заказчика. Ключевым критерием при выборе решения, которое поможет вам не только выполнить локальную текущую задачу, но и развивать существующие бизнес-процессы, является возможность развития. Как и для «естественного» интеллекта человека.
|
Чем выше потенциал развития как со стороны вендора, так и со стороны пользователей решения и чем больше кейсов заказчик может закрыть одним набором инструментов, тем выше ценность предлагаемого продукта. |
Похожие статьи



ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 0