
Нечеткий поиск и его роль в цифровой трансформации

Нечеткий поиск позволяет «прощать» пользователям опечатки в запросах и прокладывает дорогу искусственному интеллекту в процессы, происходящие в ECM-системах. Тем самым он становится еще одним дорожным камнем на пути цифровой трансформации организации.
Все мы в повседневной жизни давно пользуемся поисковыми системами, такими как Яндекс или Google, чтобы найти необходимую нам информацию. С каждым годом поисковые системы учатся понимать нас всё лучше, предлагают в результатах наиболее походящие запросы, чтобы мы не тратили много времени на просмотр поисковой выдачи.

Как бы нам хотелось, чтобы поиск информации внутри корпоративной сети проходил так же быстро и сразу же показывал нужный результат. Одним из инструментов решения этой задачи является нечеткий поиск.
Что такое нечеткий поиск?
В русской версии Wikipedia, к сожалению, нет статьи на эту тему, но вот что нам говорит англоязычная статья о Fuzzy Search:
В компьютерной науке приблизительное совпадение строк (или иными словами нечеткий поиск строк) это техника подбора строк, которые приблизительно (но не точно) совпадают с шаблоном. Вопрос нахождения приблизительно похожих строк обычно разделяют на 2 составляющих: нахождение приблизительно похожей подстроки в заданной строке, нахождение строки словаря которая приблизительно соответствует шаблону
Давайте попробуем сформулировать простыми словами, что же это такое и как нечеткий поиск относится к цифровой трансформации предприятия.
В первую очередь предлагаю выделить в контексте работы большинства организаций основные бизнес-кейсы, в которых требуется найти не точный, а приблизительный результат.
1. Поиск информации в какой-либо корпоративной информационной системе (КИС). При этом пользователь, осуществляющий запрос, может ошибаться в написании слов, но в целом поисковая строка соответствует содержимому КИС.
2. При внесении данных в базу была допущена ошибка в написании, и к этим данным происходит запрос. Ситуация дополняет предыдущую, но при этом содержимое КИС может отличаться от правильного написания, а пользователь также может допускать ошибки в поисковом запросе.
3. Необходимо подставить значение в заполняемый реквизит, при этом точное написание реквизита неизвестно (например, имя Олеся или Алеся, Данил или Даниил). В этом случае при поиске записи справочника по четкому совпадению может вернуться пустой результат, если введенное значение отличается от указанного в системе.
Все приведенные кейсы так или иначе связаны с хранением информации и её поиском. Больше всего текстовой информации содержится в документах, а работа с ними, как правило, происходит в контексте ECM-систем. Рассмотрим этот случай более подробно.
Нечеткий поиск в контексте ECM-системы
Ввод документов в ECM-систему — один из важных этапов управления контентом в крупной компании. В качестве отправной точки рассуждения рассмотрим следующий кейс:
|
1. С помощью средств распознавания получен текстовый слой в отсканированном документе. 2. Написание реквизита в текстовом слое отличается от реально написанного в связи с погрешностью алгоритмов распознавания. 3. Необходимо найти и заполнить карточку документа данными на основании распознанных реквизитов. |
Стоит начать с того, что средств распознавания текста в корпоративном сегменте становится больше. От давно известных решений, до недавно появившихся, но активно развивающихся и обгоняющих опытных конкурентов.
В общих чертах логика их работы в процессе потокового ввода может быть представлена следующим образом:
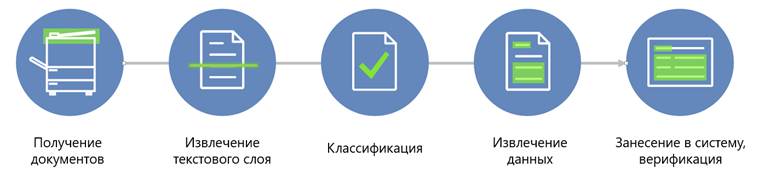
Различие решений по вводу и распознаванию — в применяемых алгоритмах работы с файлами и текстом. Каким-то инструментам требуется вмешательство человека для определения областей с нужными реквизитами в документе, а другие умеют самостоятельно на основе машинного обучения извлекать необходимые реквизиты.
Казалось бы, на схеме нет этапа, включающего нечеткий поиск. Но если немного порассуждать, то мы заметим, что извлеченные данные необходимо занести в систему и после этого проверить корректность их заполнения. Как раз на этапе занесения информации и используются алгоритмы нечеткого поиска.
В условиях нашего кейса написание реквизитов в извлеченном тексте отличается от информации в базе (например, Авангард ООО и Общество с ограниченной ответственностью «Авангард»).
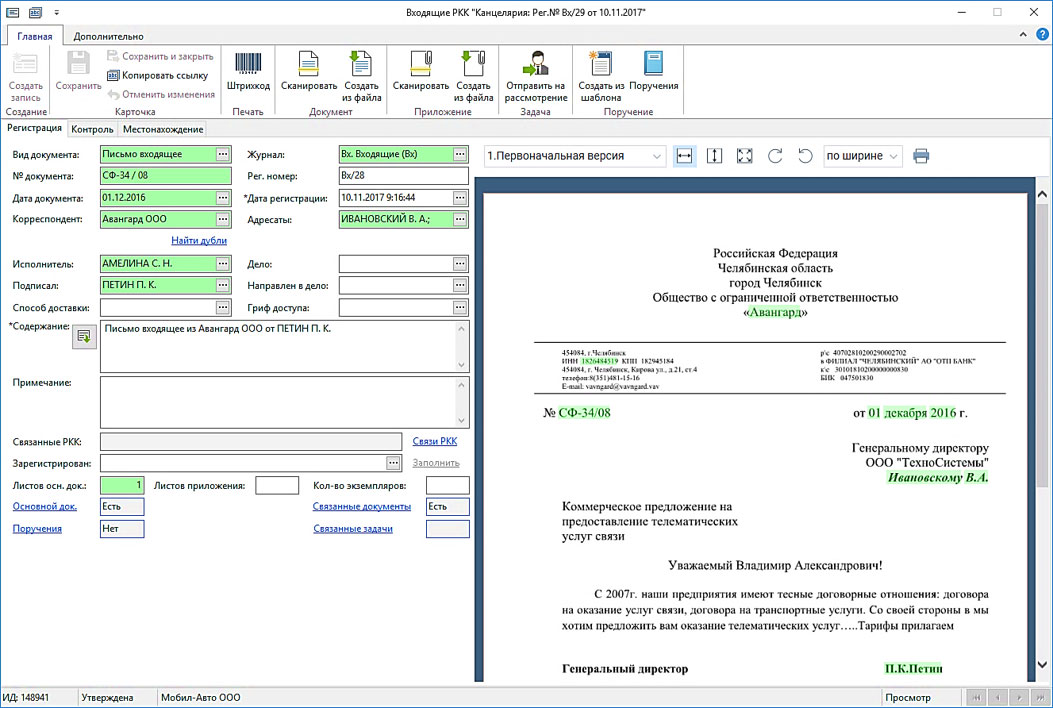
Для подбора подходящих значений используются разные алгоритмы, например:
● измерение расстояния Дамерау-Левенштейна,
● линейный поиск,
● алгоритмы расширения выборки,
● поиск с использованием алгоритма Bitap.
Каждый из них дает разные результаты по точности и скорости поиска. Поскольку речь идет о ежедневном применении в ECM-системе, важно выбрать алгоритм, показывающий наилучший результат при высоких требованиях к скорости обработки. Наши исследования показывают, что лучше всего по этим параметрам себя показывает алгоритм измерения расстояния Дамерау-Левенштейна. Именно он в данный момент используется в DIRECTUM Ario.
Нечеткий поиск позволяет «прощать» пользователям опечатки в запросах и прокладывает дорогу искусственному интеллекту в процессы, происходящие в ECM-системах. Тем самым он становится еще одним дорожным камнем на пути цифровой трансформации организации.
Роль нечеткого поиска в цифровой трансформации
Много статей уже написано про цифровую трансформацию современного бизнеса и пересказывать их содержание мы не будем. Стоит акцентировать внимание на том, что этот популярный термин — совсем не про «автоматизацию бизнеса». Основной задачей цифровой трансформации является преобразование существующих бизнес-моделей изнутри, способное стать революционным толчком к развитию (в отличие от эволюционного пути автоматизации). Компаниям важно понимать, как именно инструменты цифровизации помогают выйти на новый уровень и обеспечить конкурентное преимущество на рынке.
Организация, идущая по пути цифровой трансформации, оставляет машинам рутинные операции и раскрывает творческие возможности каждого работника. Сотрудники могут изобретать новые способы увеличения доходов компании, пока новые инструменты обеспечивают надежный тыл за счет автоматизированных типовых операций без вмешательства человека.
Соответственно, принято выделять 2 составляющие цифровой трансформации: революционно-творческую или эволюционно-автоматизируемую — одна из них обеспечивает тот самый «тыл», а вторая поддерживает внутренние инновации. Давайте попробуем разобраться, какую роль в этом процессе занимает нечеткий поиск. Для этого выделим основные признаки составляющих:
1. Революционно-творческая
a. Свобода выполняемых действий.
b. Прогнозирование вероятностных результатов.
c. Поддержка нестандартных подходов.
2. Эволюционно-автоматизируемая
a. Четко выстроенные последовательные этапы.
b. Конечное количество вариантов развития событий.
c. Существование единственно верного конечного результата.
Нечеткий поиск дает вероятностный результат и используется в случае, если обычные механизмы не могут принести ожидаемый эффект. Исходя из этого, можно отнести его к революционно-творческой составляющей цифровой трансформации.
Без использования нечеткого поиска невозможно представить работу в информационной среде, содержащей вероятностные результаты. Обычные механизмы, такие как elastic search, не дают возможности пользователю увидеть весь набор результатов поиска с учетом возможности отклонения от нормы (наличия ошибок в написании слов в составе запроса или ответов). Использование новых алгоритмов обеспечивает покрытие крайних результатов поиска информации и тем самым не оставляет «слепых зон» или пробелов в отображаемой информации.
Машина наконец переходит грань, когда она не просто «сравнивает две строки», а может как человек «понять», что имел скорее всего в виду пользователь, но просто написал с сокращением, с ошибкой, в обратном порядке и т.д.
Вместо заключения
Руководители и ИТ-директора крупных и прогрессивных компаний при выборе ИТ-решений ставят наличие искусственного интеллекта на одно из первых мест. Применение нечеткого поиска является весомым аргументом в пользу таких продуктов как, например, DIRECTUM Ario. В комплексе с другими технологиями Ario обеспечивает возможность более качественного заполнения всех реквизитов документа, пополняя базу структурированной информации и освобождая пользователя от необходимости тратить рабочее время на поиск данных, которые за него может найти система.
Вся описанная выше информация является лишь попыткой перевести на язык рядовых пользователей описания одного из мощнейших инструментов, использующегося в механизмах цифровой трансформации. Безусловно, это всего лишь малая часть из того числа технологий, которые необходимо внедрять в современных информационных системах, чтобы они были конкурентоспособными на современном рынке.
Источник: DIRECTUM
Похожие статьи



ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 0