
Бумага в электронном документообороте или Образное мышление
В ближайшее время сохранится необходимость работать с документами сразу в двух формах: в бумажной и в электронной. Поэтому компаниям нужно четко представлять, как организовать такую работу.
Михаил Романов, ИТ-аналитик компании DIRECTUM
В ближайшее время сохранится необходимость работать с документами сразу в двух формах: в бумажной и в электронной. Поэтому компаниям нужно четко представлять, как организовать такую работу.
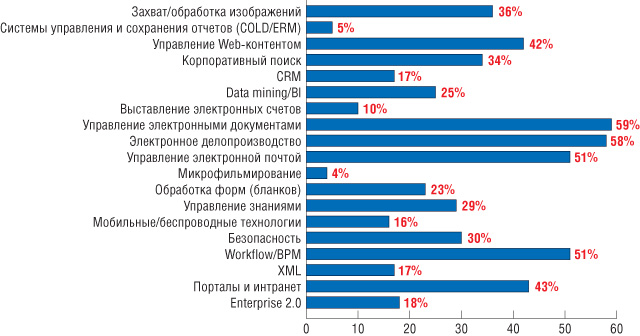
По результатам опроса международной ассоциации AIIM (Association for Information and Image Management), проведенного в начале 2008 г. среди нескольких сотен организаций в США, Великобритании, Австралии и некоторых других англоговорящих странах, выяснилось, что 36% организаций планируют проекты, связанные со сканированием бумажных документов и обработкой образов, в ближайший год-полтора (рис. 1). А предприятия, уже внедрившие ECM-системы, ожидают у себя роста объемов задач ввода и распознавания документов.
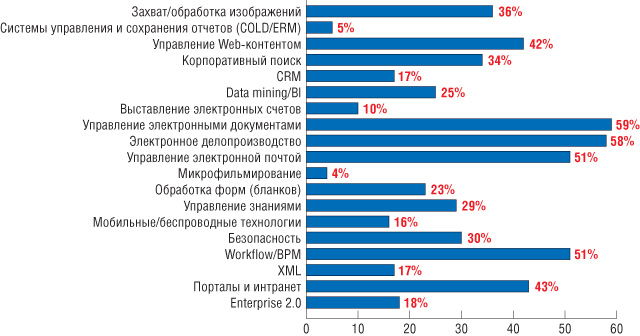
Рис. 1. Какие
технологии будут интересны организациям в следующие 12–18 месяцев.
Источник: обзор AIIM State of the ECM industry, March 2008.
Зачем компаниям такие сложности с бумагой? Ведь сегодня документы в большинстве своем появляются в электронном виде; электронные документы удобнее хранить, ими удобнее обмениваться, информация в них точнее. И все же по ряду причин многие документы до сих пор обязательно существуют в бумажном виде: например, первичные бухгалтерские документы из-за требований законодательства должны быть бумажными и содержать «живые» подписи и печати*.
Договоры, фискальная отчетность и некоторые другие типы документов, по взаимному согласию сторон, уже могут существовать в электронном виде: недаром появляются различные сервисы для работы с документами в электронной форме. Тем не менее, даже при наличии законодательной поддержки от бумажных документов этих типов нелегко отказаться. Придется менять регламенты самого предприятия, его контрагентов, а в перспективе — отрасли в целом. Нужен общий переход на электронный документооборот, но большинство организаций к нему пока не готово.
Другой вид сохраняющихся сегодня бумажных документов — это документы, которые удобнее заполнять на бумаге: анкеты, заявления, декларации. Существует также множество унаследованных бумажных документов (чертежей, схем, инструкций).
Без бумаги никуда, а с бумагой — неудобно. И поэтому многие уже сегодня считают экономически оправданным перевод документов в электронный вид, несмотря на дополнительные затраты на сканирование и распознавание бумажных документов.
Электронно-бумажные задачи
Итак, в ближайшее время сохранится необходимость работать с документами сразу в двух формах: в бумажной и в электронной. Чтобы упорядочить представление о том, как организовать такую работу, рассмотрим следующие вопросы:
● какие задачи чаще всего возникают на стыке бумажной и электронной формы документа;
● какие существуют методики для решения этих задач;
● каковы «лучшие практики» в области электронно-бумажных документов.
Для начала выделим основные направления электронно-бумажного взаимодействия.
Идентификация. Основная задача идентификации — быстро найти электронный объект, связанный с бумажным документом. Например, от партнера вернулся подписанный им договор (ранее документ уже был подписан вами). Ваша задача — быстро найти документ в системе управления договорами и запустить работы по нему.
Ввод неструктурированных документов. Под вводом неструктурированных документов мы подразумеваем весь спектр задач перевода бумажных документов в электронный вид, при которых не требуется дальнейшая машинная обработка. Все действия над документами (правка, копирование отдельных частей в другие документы или просто просмотр) в данном варианте выполняются людьми вручную.
Извлечение данных. Здесь основной упор делается на дальнейшую обработку документов автоматическими методами. При извлечении данных документ нужно не просто оцифровать, но и «прочесть» и правильно интерпретировать. Примером служит оцифровка структурированных документов (платежных документов, счетов-фактур, паспортов).
Безусловно, кроме идентификации, ввода документов и извлечения данных (о которых подробно будет рассказано ниже) важен и этап размещения документа в хранилище. Оцифрованный и обработанный образ документа уходит в электронное хранилище, а бумажный документ — в архив организации. Задачи на этом этапе таковы: обеспечить на будущее удобный доступ к документу, правильным образом разместив его в структуре электронного хранилища (например, сложив в нужные папки), связав с позицией в бумажном архиве, заполнив атрибуты и назначив необходимые права доступа.
Идентификация
Для каких задач может применяться идентификация? Вот лишь несколько примеров. Быстрый поиск электронного документа в хранилище в момент подписания бумажной копии, нужен, например, чтобы сравнить бумажный и электронный варианты, поставить подпись на электронный вариант и т. д. Поиск ранее распечатанного отчетного документа может потребоваться, скажем, когда водитель возвращает путевой лист диспетчеру, для отметки и внесения данных из листа в учетную систему. Как бы ни хотелось заносить все данные из такого документа в систему автоматически, это практически неосуществимо, поскольку заполняются такие документы «на скорую руку», неразборчиво. Да и сами документы иной раз доведены до такого состояния, что не только машине, но и опытному оператору не разобрать.
Основная идея всех методов идентификации состоит в нанесении на идентифицируемый объект уникальных меток, которые впоследствии легко и быстро считываются. При разработке решений для идентификации возникает довольно много вопросов, основные из которых таковы:
● какой тип меток использовать;
● как наносить метки: как правильно выбрать идентификатор для занесения в метку, где располагать метку, как обеспечить ее сохранность и долговечность;
● как эффективно организовать считывание и обработку меток.
Какой тип меток использовать
В настоящее время существует огромное количество способов и методов нанесения меток на бумажные носители. Условно их можно разделить на две категории: человекочитаемые метки (номера, буквенно-цифровые коды) и машиночитаемые. Последние бывают визуальными (машиночитаемые шрифты, графические идентификаторы-метки, штрихкоды) и невизуальными (RFID-метки).
Из этого списка можно убрать практически вышедшие из употребления машиночитаемые шрифты (рис. 2) и графические методы. Придется также отбросить RFID-метки из-за их более высокой по сравнению с прочими методами стоимостью. К тому же невизуальность RFID-меток делает невозможным считывание их вручную в отсутствие считывающего оборудования.
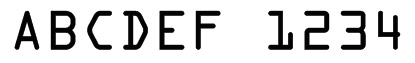
Рис. 2. Пример машиночитаемого шрифта.
Остаются обычные цифровые или буквенно-цифровые коды, которые вводятся вручную, и штрихкоды. Выбор между этими двумя технологиями определяется, во-первых, количеством документов, которые нужно помечать (а соответственно и длиной кода, который придется вводить вручную); во-вторых, частотой использования (как часто требуется искать объект) и количеством мест, на которых этот поиск востребован, т. е. общей стоимостью решения.
В настоящее время наиболее технологичное и распространенное решение — это штрихкодирование, однако это не значит, что другими технологиями можно пренебречь. Авторам известно промышленное предприятие, в конструкторских бюро которого с успехом была внедрена система идентификации бумажных чертежей, основанная на пятизначном коде, вводимом руками с клавиатуры. Кроме того, стоит отметить, что развивающиеся сегодня технологии голосового управления позволяют реализовать схемы, в которых человек-оператор читает вслух код метки, распознаваемый и интерпретируемый компьютером. Правда, подобные технологии достаточно дороги и распространены только в специализированных отраслях (например, в складской логистике).
Как наносить и считывать штрихкоды
Штрихкодами никого не удивишь: они успешно используются для маркировки готовой продукции, для кодирования информации о весе/цене товара и в сотнях других решений. Однако в штрихкодировании (а особенно при использовании штрихкодов в работе с электронно-бумажными документами) есть свои тонкости и нюансы.
Штрихкод — понятие очень емкое и включает различные способы визуального кодирования информации в виде набора рисок-штрихов. Широко распространенные в настоящее время штрихкоды, во-первых, двухцветные (черные линии на белом фоне), а во-вторых, делятся на линейные (1D) и двумерные (2D). В каждой из подгрупп имеется огромное количество различных стандартов кодирования (рис. 3); при выборе системы штрихкодирования следует учитывать максимальную длину сообщения, компактность (число знаков на площадь штрихкода), поддерживаемый алфавит, контрольные суммы, помехоустойчивость и распространенность, т.е. поддержку производителями средств считывания и распознавания.

Рис. 3. Примеры штрихкода: а) нотация Code128; б) PDF-417; в) DataMatrix; г) QRCode.
При нанесении штрихкода и выборе места его расположения на документе важно обеспечить легкость и качество его дальнейшего считывания. При этом необходимо учитывать следующее: долговечность и устойчивость к стиранию (например, термопринтеры штрихкодов печатают быстро выгорающие метки, подходящие лишь для ценников в магазине); устойчивость к помаркам при передаче документа из рук в руки; физические размеры (штрихкод не должен мешать чтению документа, но при этом должен считываться устройствами с низкой разрешающей способностью).
Штрихкоды можно впечатывать, наклеивать, наносить на отдельный лист и прикреплять к документу. Это, как и состав сообщения штрихкода (идентификатор документа, дата, номер и т. п.), зависит от конкретных сценариев, в которых будет применяться штрихкод.
Ввод документов
Прежде чем переходить к прочим направлениям, договоримся о терминологии — что понимать под структурированными и неструктурированными документами.
Под структурированными мы будем понимать такие документы, для которых можно точно указать местоположение отдельных информационных блоков (даты, названия, суммы). Местоположение может указываться любым способом; главное, чтобы заданные правила легко могли быть повторены компьютером на всех аналогичных документах. Примеры структурированных документов — это анкеты, счета-фактуры (при условии, что мы рассматриваем счета-фактуры от одного поставщика — только в этом случае можно говорить о сходных правилах построения документа, у различных же поставщиков формы счетов-фактур будут различаться).
Неструктурированными будем называть все документы, для которых задать правила извлечения отдельных информационных блоков:
а) невозможно (пример — технический проект или аналитическая записка, содержащие неформальное описание изучаемого объекта);
б) сложно и дорого (например, автоматически извлечь из договора названия, даты, сроки договора в принципе возможно, но настройку такого шаблона придется делать для каждого типа договора с каждым партнером/клиентом);
в) нецелесообразно. Пожалуй, это самый главный критерий: зачем извлекать данные из документов, которые хранятся только на случай возникновения какой-то редкой спорной ситуации (связанной с трудовыми отношениями или конфликтом с партнером/клиентом).
Неструктурированные документы
Попробуем разобраться, для каких целей может понадобиться ввод неструктурированных документов. Цели каждого предприятия могут различаться весьма существенно, но есть несколько задач, которые встречаются почти у всех.
Создание архива для целей compliance (удовлетворения требований контролирующих органов, инвесторов или просто внутренней политики предприятия по сохранению любой значимой информации). Необходимость обращения к таким архивам возникает нечасто: это некоторые регулярные проверки или нештатные ситуации, связанные с обращением в судебные инстанции. Особенности данной задачи в том, что к таким документам, возможно, не будут обращаться совсем, и такие документы должны быть неизменны. Для гарантии их неизменности используются специализированные аппаратно-программные решения.
Изменение исходного бумажного документа. Простейший пример: в пришедшем к вам на подписание договоре имеется ошибка. Чтобы не ждать, пока приславшая сторона вышлет новый вариант, вы могли бы ее исправить и подписать договор сами, но партнер по какой-то причине отказывается прислать исходный электронный вариант. Для этой задачи основным требованием будет точный (до символа) перевод в электронный вид с сохранением форматирования. Существующие на сегодняшний день методы распознавания, увы, требуют обязательного контроля полученного результата (а нередко и серьезной правки — в зависимости от качества отсканированного документа и сложности его форматирования).
Создание обрабатываемой базы знаний/фактов. Основное отличие от первого варианта состоит в том, что поиск по такой базе будет идти по содержимому документа, а не по приложенной к документу метаинформации (карточке документа), т. е. документ здесь важен как носитель информации, а не как отражение какого-либо факта. Для того чтобы документ можно было найти среди разнообразных поступающих в систему данных, бумажный документ требует распознавания. В то же время нет необходимости сохранять исходное форматирование документа (он используется только для внутренних целей). Кроме того, для целей полнотекстового поиска вполне допустим небольшой процент нераспознанных слов. Таким образом, для задачи создания информационной базы вполне подходит распознавание текста в автоматическом режиме.
Одна из основных сложностей, возникающих при вводе неструктурированных документов, — большой объем сканируемых документов. К сожалению, большинство документов, попадающих под определение «неструктурированных», имеют две не очень приятные в плане автоматизации особенности, а именно: их необходимо предварительно расшивать, и невозможно автоматически извлечь из документа данные для его регистрации.
Для решения последней задачи нужно максимально упрощать регистрацию, вплоть до того, что карточка документа не будет содержать ничего, кроме даты. Однако в дальнейшем работать с таким документом будет проблематично. Другой вариант — регистрировать документы вручную, до или после сканирования и распознавания.
С необходимостью же предварительного расшивания документов бороться сложно. Большинство многостраничных официальных документов передается в сшитом виде (они скреплены канцелярскими скрепками, сшиты тесьмой и т. д.). Такие документы непригодны для сканирования на обычных потоковых сканерах. Остается отказаться от сканирования подобных документов, или расшивать их (что не всегда допускается), или использовать ручное сканирование на планшетном сканере. Остальные методы — например, с использованием книжных листающих сканеров, — оказываются не быстрее и многократно дороже.
Выбор сценария ввода
Теперь, разобравшись с основными проблемами, рассмотрим некоторые факторы, определяющие выбор сценария ввода документов.
Кто вносит документы. Возможен полностью централизованный ввод, которым занимаются выделенные сотрудники-операторы. При этом мест приема документов и ввода может быть больше одного. Другой вариант — децентрализованный ввод, когда вводом занимаются все сотрудники. Здесь нужно понимать, что речь идет именно о процессе ввода/сканирования, но не о регистрации документов (которую даже в случае децентрализованного ввода могут выполнять специально обученные люди).
Каков объем входящей корреспонденции и как этот объем распределяется по местам регистрации/сканирования.
Перечисленные два фактора, а также пригодность основного потока документов к потоковому сканированию (на это влияет, в частности, процент документов, требующих расшивки или ручного сканирования) определяют возможную схему организации сканирования:
● ручное на планшетном сканере;
● на совместно используемом несколькими сотрудниками потоковом сканере;
● на настольном потоковом сканере (у каждого сканирующего свой аппарат);
● на профессиональных потоковых сканерах (как правило, отдельными людьми в отдельном помещении).
Когда происходит регистрация документа: до или после перевода в электронный вид. Например, предварительная регистрация актуальна для организаций, где все официальные входящие документы первым делом попадают на рассмотрение руководителю и лишь после этого вместе с рецензией заносятся (или не заносятся) в систему электронного документооборота или архив.
Важен также ответ на вопрос, где первоначально регистрируют документ: в системе электронного документооборота (т. е. там же, где будет храниться образ документа) или в иной информационной системе (АБС, ERP, CRM и т. д.).
Идентификационные метки на документах: используется глобальное нанесение меток или нет (метки не наносятся или наносятся эпизодически).
Эти факторы определяют порядок операций сканирования, нанесения меток и регистрации документов. Для больших объемов входящих документов с централизованной обработкой нередко используется следующий сценарий.
1. Документ поступает в канцелярию и передается одному из делопроизводителей на обработку.
2. Делопроизводитель, если нужно, расшивает документ, регистрирует его в СЭД (или учетной системе) и наносит на документ штрихкод (который уникально идентифицирует регистрационную запись о документе), а затем передает документ на сканирование.
3. Оператор сканирования принимает комплект расшитых документов и сканирует их на потоковом сканере, затем передает документы на сшивку (если требуется) и занесение в архив.
4. ПО, принимающее документы с потокового сканера, выполняет поиск и чтение нанесенных на документ штрихкодов. По найденным штрихкодам происходит как разделение всего потока страниц на отдельные документы, так и поиск регистрационной информации и занесение документа в систему хранения, а также заполнение атрибутов его карточки (или привязка к ранее созданной).
Какая обработка требуется для отсканированных документов. В основном пост-обработка документов сводится к смене формата электронного документа или параметров формата (изменение разрешения изображений для сокращения объемов хранимой информации, поворот, отсечение границ).
В каком виде (формате) будет храниться документ. Это может быть только изображение, либо изображение с фоновым текстом, либо обычный редактируемый документ.
Камнем преткновения при выборе методов для обработки отсканированных документов становится вопрос: распознавать или не распознавать документы? А если распознавать, то каким способом (хотелось бы автоматически). Ответ, как обычно, резонерский: в зависимости от потребностей. Возвращаясь к выделенным в начале обсуждения задачам ввода неструктурированных документов, все потребности можно свести к трем:
● поиск по тексту документов;
● возможность изменения исходного документа;
● получение «плавающих» форматов (допускающих удобный показ на неформатных экранах, в первую очередь на экранах мобильных устройств).
Наиболее требовательно распознавание для изменения исходного документа — в этом случае требуется подключить к процессу распознавания операторов для контроля качества и исправления ошибок.
Наименее требовательно распознавание для поиска — в этой задаче небольшим количеством ошибок распознавания можно пренебречь, процесс может идти целиком автоматически.
Несколько неопределенным остается вопрос с «плавающими форматами», но здесь требования ближе к распознаванию для редактирования с той лишь разницей, что не требуется сохранять исходный формат.
Что касается выбора формата для хранения, то он определяется тем, будет ли документ распознаваться и каким именно образом. Таким образом, возможны следующие варианты форматов хранения.
Только изображение. Наиболее часто хранится в формате TIFF, учитывая поддержку полутоновых и черно-белых изображений и многостраничности.
Изображение плюс текст. Очень удобный вариант для занесения всего потока входящих документов. С одной стороны, не теряется информация изображения, можно в любой момент из документа получить редактируемый вариант; с другой — наличие текста делает возможным некоторую автоматическую обработку, как минимум индексирование и выдачу в результатах поиска дайджеста документа. Такой возможностью обладают многие распространенные форматы (в частности, PDF и DjVu);
Обычный редактируемый документ. Это собственно документ с форматированием, имеющий формат используемого в организации офисного пакета.
Извлечение данных
Читая о методах ввода неструктурированных документов, можно подумать, что работа с бумажными документами остается насквозь ручной. К счастью, это не так, ибо существует обширная область, в которой участие человека минимально или вообще не требуется. Это извлечение данных из машиночитаемых меток и обработка бумажных форм.
Извлечение данных из меток
Наиболее часто используемая методика — дублирование информации документа в двумерном штрихкоде, размещаемом на том же листе (одномерные штрихкоды здесь проигрывают из-за малого хранимого объема, а радиометки — по причине дороговизны).
Приведем один из возможных сценариев использования двумерных штрихкодов — занесение в систему договоров на страхование физических лиц. Сценарий примерно такой: имеется большое количество страховых агентов, у которых есть необходимое оборудование для набора и печати электронных документов, но нет возможности автоматически передавать информацию в центр обработки (это может быть удаленный офис или мобильный агент в автомагазине). Кроме того, практически все документы должны быть подписаны застрахованным лицом (и остаются все те же вопросы с одновременным занесением документов).
Этапы решения таковы:
1. Данные клиента вносятся в специальную программу, которая печатает все документы, одновременно размещая всю необходимую информацию в двумерных штрихкодах.
2. Клиент сверяет и подписывает документы.
3. Документы передаются в центр обработки, где заносятся в систему.
В этом сценарии, как и в ряде других, и подготовка, и ввод документов ограничены одной организацией. Это не случайно: согласовать форму документов, передаваемых между организациями, с внедренным штрихкодом — достаточно сложная задача. Ее можно полностью решить разве что в холдинговых структурах или в банках-гигантах и государственных органах.
Извлечение данных из форм
Второй вариант извлечения данных из бумажных документов связан с обработкой форм. В технологиях обработки принято деление форм по степени их пригодности к извлечению данных (или качества). Формы делятся на жесткие (машиночитаемые) и на гибкие (плавающие).
Жесткие формы в соответствии с названием характеризуются жестким фиксированным расположением полей ввода, одинаковым на всех листах. Такие формы используются для ввода анкет, тестирования, т. е. документов, заполненных на заранее подготовленных бланках (рис. 4).

Рис. 4. Пример жесткой формы — анкета посетителя выставки.
Плавающие же формы не имеют жесткого расположения полей. Поля определяются по их расположению относительно других элементов разметки, по форматированию и т. д. Описание такой формы — дорогая и трудоемкая задача. Кроме того, в некоторых случаях для ввода даже одного типа документов (например, счетов-фактур), потребуется создавать свое описание для каждого начертания документа, так как два документа практически невозможно описать с помощью одного шаблона. Тем не менее, сколь бы ни была сложна разработка шаблона формы, она, как и любой подготовительный этап, выполняется единожды, а затем используется для многократного ввода собственно форм.
Однако и у самого процесса ввода данных есть свои особенности. В первом приближении процесс ввода состоит из следующих шагов: подготовка документов, сканирование, распознавание, верификация, выгрузка данных в принимающую систему или системы (рис. 5).
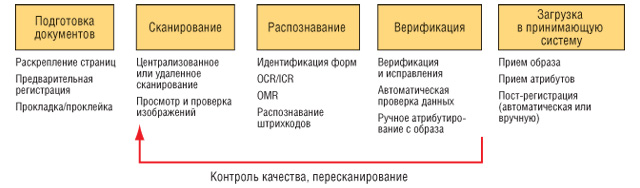
Рис. 5. Этапы обработки форм.
Если этапы сканирования, распознавания и выгрузки интуитивно понятны, то по поводу верификации нужно сказать особо. К сожалению, развитие технологий оптического ввода не обеспечивает 100%-ной точности ввода текстов. Поэтому при распознавании для ввода данных используют техники, повышающие процент «угаданных» символов и проверяющие корректность полученных данных. В конечном счете, решение о том, как именно трактовать тот или иной символ или данные, принимает человек, занимающийся верификацией. Поэтому процессы ввода данных из форм, никогда не бывают полностью автоматическими.
Что осталось за бортом
За рамками статьи осталось еще много вопросов. Мы не стали детально рассматривать конкретные сценарии ввода и обработки образов. Нет рекомендаций по выбору средств хранения или распознавания документов. Не дана оценка скорости извлечения данных. Не рассказано о требуемых объемах хранилищ образов документов и возможной загрузке каналов. Это, как и многое другое, темы отдельных обзоров и статей.
С уверенностью можно сказать одно — универсальных рецептов в области ввода, преобразования и хранения образов документов будет немного. Каждая организация — это уникальная задача, уникальные требования и уникальные решения. И качество конкретных платформ и инструментов для решения этих задач будет определяться удобством и легкостью адаптации к конкретным потребностям.
* См. С.Бушмелев «В электронном нельзя в бумажном»
Источник: BYTE
Похожие статьи


ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 6
Михаил пишет "К тому же невизуальность RFID-меток делает невозможным считывание их вручную в отсутствие считывающего оборудования."
Хочется задать вопрос: а что, штрих-коды можно запросто считать вручную, особенно двумерные? На случай отказа оборудования, под штрих кодом помещают обычный текст - и что мешает сделать то же самое на RFID-метке? На практике достаточно часто RFID-метка снабжается и равноценным штрих-кодом, и обычным текстом.
Согласен, с RFID-ом вполне можно поступить как со штрих-кодом, нанести на него и надпись, и даже штрих-код. Правда, если штрих-код уже есть, то зачем еще RFID - по крайней мере с ходу прямых достоинств я не вижу (я имею в виду для нанесения на бумагу). Но объем статьи и так пришлось ужимать, нужно ж было как-то объяснить, почему про RFID (наверное, самой популярной после штрих-кодирования технологии на сегодня) - ни слова :).
Ну а если серьезно, то основным вопросом, все-таки, остается стоимость. Если использовать дешевые метки с вшитым ID, то стоимость будет не заоблачной, но все больше чем рулончика клеящей ленты. А если брать перепрограммируемые, в которые можно вносить свои данные (и на которые потом надпечатывать свою аннотацию), то стоимость возрастает очень ощутимо.
Второй момент - по сравнению даже с клеящей лентой (а уж с надпечаткой на саму бумагу и подавно) RFID и жестче и толще, а значит, если наносить метку до сканирования, нужно подбирать соответсвующий сканер (лучше всего тогда не протяжный, а они - самые распространенные из поточных). Конечно, все потихоньку меняется (была даже идея с появлением гибкой электроники внедрять метки сразу в структуру бумаги) - но результатов я пока не знаю, может что и получилось уже.
И еще один момент, который мне не нравится в использовании RFID-ов для документов. На исходящие документы мы можем штрих-код нанести сразу при печати (вставив в документ, или нанеся во время печати через обработчик потока печати, ...), а вот RFID-придется наклеивать все равно.
Примерно так...
Из серьезных же плюсов RFID-ов я пока вижу только, возможно, большую долговечность по сравнению со штрих-кодами, т.к. они не подвержены истиранию (бич всех визуальных меток). Однако, точных данных о долговечности RFID-ов у меня, к сожалению, нет.
Возможно я еще что-то упустил. Если так, то буду рад подсказке! Возможно, я слишком критичен к этому виду меток.
Главное достоинство RFID - это, все же, не долговечность, а возможность дистанционного считывания без необходимости прямой видимости. Что позволяет построить, например, полностью автоматическую систему контроля за перемещением бумажных документов (и не только документов, конечно).
Что позволяет построить, например, полностью автоматическую систему контроля за перемещением бумажных документов (и не только документов, конечно).
Увы, но с ходу я не могу назвать ни одной задачи, где бы такое потребовалось.
Увы, но с ходу я не могу назвать ни одной задачи, где бы такое потребовалось.
Как насчет блокировки выноса конфиденциальных документов с территории предприятия? От целенаправленного промышленного шпионажа это, пожалуй, не спасет. Но вот если сотрудник хотел взять работу на дом и прихватил конфиденциальный документ - система ему скажет: "Нельзя!".
Да,
слона-то я и не приметилпро самое главное совсем забыл написать :-)Бумажные документы - это не только приказы или договора. Это еще, например, паспорта и пропуска. При помощи RFID можно построить систему доступа (с разграничениями уровней по различным зонам предприятия) аналогичную системам конактного сканирования пропусков. Но это будет несколько удобнее. Документ, удостоверяющий личность банально не надо доставать из кармана.