
Обработка знаний: технологии анализа и поиска текстовой информации
Развитие индустрии СЭД, сопровождающееся ростом массивов обрабатываемых полнотекстовых документов, требует новых средств организации доступа к информации, многие из которых следует отнести к разряду систем искусственного интеллекта.
Введение
Развитие индустрии систем электронного документооборота, сопровождающееся ростом массивов обрабатываемых полнотекстовых документов, требует новых средств организации доступа к информации, многие из которых следует отнести к разряду систем искусственного интеллекта - систем обработки знаний.
Основной задачей, возникающей при работе с полнотекстовыми базами данных, является задача поиска документов по их содержанию. Однако, ставшие традиционными средства контекстного поиска по вхождению слов в документ, представленные, в частности, поисковыми машинами в интернет, зачастую не обеспечивают адекватного выбора информации по запросу пользователя.
Основная проблема заключается в сложности точной формулировки запроса – подбора ключевых слов, которые предстоит искать в телах документов. Это может быть связано с рядом причин, как-то: недостаточным знанием пользователем терминологии предметной области, наличием в языке многозначных и синонимичных слов, и даже орфографическими ошибками в написании искомых слов, которые могут встречаться как в текстах, так и в самом запросе.
Другая фундаментальная причина заключается в том, что иногда пользователь не знает точно, какую именно информацию ему хотелось бы получить, имея лишь общее представление о границах своих интересов. Так, например, пытаясь расширить свои познания в области компьютерной лингвистики, на поисковом сервере AltaVista вы просто получите список из сотен тысяч документов, содержащих слова «computer» и «linguistic». А ведь хотелось бы расклассифицировать найденный материал по тематическим группам, отражающим, к примеру, основные событиям и разработки в этой области! И хотя наиболее интересен тот материал, о присутствии которого вы вообще не догадываетесь, большинство поисковых машин предлагает найти информацию «под фонарем», а не там, где она зарыта!
Чтобы помочь в решении указанных проблем, мы разработали ряд технологий, предназначенных для автоматического анализа содержания текстовых документов и выявления основных смысловых единиц, работа с которыми призвана облегчить процессы визуализации и поиска информации. Выявление смысловых структур, в сжатом виде описывающих основное содержание текстового материала, основано на модели механизмов обработки информации правым полушарием человеческого мозга.
Многие годы разработчики «искусственного интеллекта» пытались научить компьютер логическому мышлению, основанному на манипулировании формализованными знаниями и правилами их преобразования. Такой тип мышления характерен для обработки информации левым полушарием мозга. Простейший пример левополушарной модели знаний представляют иерархические рубрикаторы, используемые в информационно-поисковых системах для классификации информации. Однако, ввиду неспособности ЭВМ к языковому мышлению, их возможности ограничены рамками изначально заложенной системы знаний. Проблема заключена в невозможности самообучения рубрикатора без участия человека.
В тоже время в мозге скрыты иные, более древние механизмы, позволяющие решать подавляющее число задач повседневной жизни без участия размышления. Эти механизмы, заключенные в правом полушарии, следует назвать ассоциативной статистической обработкой. Вся живая природа «обучалась» именно так – развивая ассоциации между связанными событиями и закрепляя рефлексы путем повторений.
Чтобы несколько прояснить эти механизмы, позволим себе аналогию со студентом, которому нужно срочно сдавать экзамен по незнакомому предмету. В этой известной ситуации есть два пути. Первый – начать с основ и, скрупулезно штудируя учебники, погрузиться в определения, изучить основные соотношения и т.д. Таков дедуктивный путь, задействующий весь арсенал ресурсов «левополушарного» мозга, который все проходили в школе, начиная, к примеру, изучение иностранного языка с грамматики. Но есть и другой подход, более быстрый. Он близок так называемому «обучению с погружением», которое применяется в интенсивных курсах обучения языку. Его и рассмотрим теперь подробнее.
Итак, студент садится за книгу и погружается в мир новой информации, проглатывая страницы одну за другой, безо всякого понимания. Однако, спустя какое-то время вдруг начинают узнаваться слова, еще не понятные, но уже знакомые. Они то и представляют ключевые понятия, на которых строится весь предмет. Правое полушарие провело статистический анализ, выделив повторяющиеся фрагменты информации, которые и образуют фундамент будущих знаний.
И студент продолжает читать, уже по второму кругу… Теперь понятия начинают обрастать неким смыслом - при встрече знакомых слов улавливается их контекст, возникают ассоциации. Так формируется и включается в работу ассоциативная семантическая сеть – комплекс связей между понятиями, увязывающий их в модель нового мира, где каждый элемент обретает собственный смысл через связи с другими. Появление связей - это опять статистика, бессознательный частотный анализ «правого мозга», который скрупулезно запоминал и оценивал, в каких комбинациях встречались понятия в тексте друг с другом.
А пока студент спит, бессознательное продолжает трудиться. Во сне происходит анализ накопленной информации - модель предмета перестраивается и совершенствуется. При этом локальные фрагменты ассоциативной сети, слабо связанные с другими, забываются и отбрасываются как случайные. Другие еще сильнее увязываются между собой, выявляются новые связи, главное и второстепенное… К утру модель предмета вчерне сформирована. И с новыми силами за предмет... Система ассоциаций включилась в работу и теперь содержание текста ясно. По мере чтения весь материал как бы нанизывается на знакомые понятия, классифицируется. Вот оно – конкретное знание по конкретным темам - в конкретных строчках! И окончательно, пробежав знакомый учебник перед экзаменом, память студента выхватывает какие-то тезисы, касающиеся главных понятий - пусть небольшой реферат останется в голове…
Проведенное художественное отступление в полной мере иллюстрирует принципы, заложенные в основу нашего подхода к анализу содержания текста.
Для интересующихся лингвистической наукой здесь доступна дополнительная информация.
О подходе
В основе процедур, используемых для анализа документов, лежит представление смысла текста в форме семантической сети.
Семантическая сеть — это множество понятий (слов и словосочетаний), связанных между собой.
В семантическую сеть включаются наиболее часто встречающиеся слова текста, которые несут основную смысловую нагрузку.
Для каждого понятия формируется набор ассоциативных (смысловых) связей, т.е. список других понятий, в сочетании с которыми оно встречалось в предложениях текста. При этом считается, что чем чаще встречаются вместе два понятия в предложениях текста, тем выше вероятность того, что они связаны по смыслу.
Оригинальные лингвистические алгоритмы позволяют отождествлять различные части речи и близкие по смыслу словосочетания. Например, такие выражения, как «подписание нескольких новых указов» и «подписал два указа», рассматриваются как одна и та же смысловая единица (одно понятие). Кроме того, из числа понятий исключаются общеупотребимые слова, которые не несут самостоятельной смысловой нагрузки или имеют широкое значение. Так, слова «концепция» и «развитие» сами по себе не являются понятиями, но могут образовать понятие, выраженное сочетанием: «концепция развития сельского хозяйства».
Таким образом, наши алгоритмы позволяют включать в число тем любые слова и их связные сочетания, например: «указ о снижении подоходного налога», и даже имена собственные, если им посвящено содержание документа.
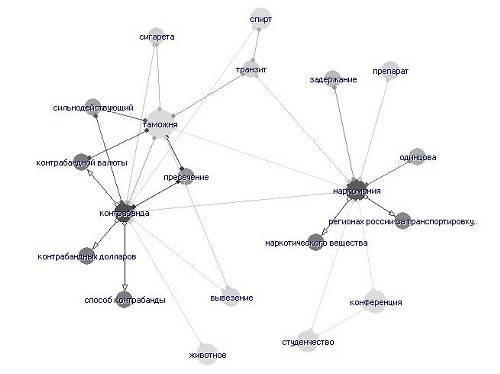
Ниже приведен рисунок с фрагментом семантической сети.
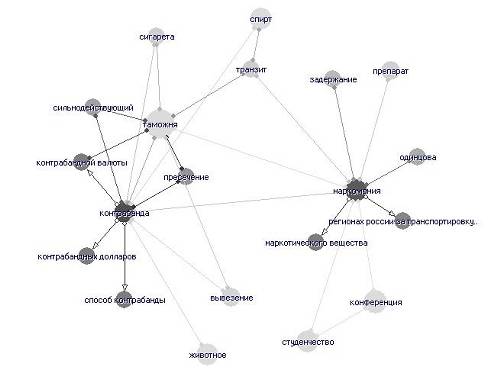
Рис. Фрагмент семантической цепи
В рамках используемой нами лингвистической модели смысла текста каждое понятие предлагается рассматривать в качестве имени соответствующей темы.
Статистические данные о связях понятий в тексте, их распределении, позволяет оценить их вклад в общее содержание текста и, таким образом, ранжировать темы по информативности. В итоге каждой теме семантической сети присваивается т.н. тематический вес.
Максимальное значение тематического веса (равное 100) соответствует ключевой (важнейшей) теме текста. Близкое к нулю значение веса темы показывает, что она лишь вскользь упомянута в тексте, и в нем мало сведений, относящихся к данной теме. Связи между парами тем, в свою очередь, также имеют характеристики — веса связей (от 0 до 100). Большое значение веса связи от одной темы к другой, близкое к 100, указывает на то, что подавляющая часть информации в тексте, касающаяся первой, касается в тоже время и второй темы — первая тема почти всегда излагается в контексте второй. Малое значение веса отражает тот факт, что первая тема слабо связана со второй (излагается независимо от нее). Связь между парой тем сети всегда двусторонняя, однако, связь от первой темы ко второй не всегда имеет тот же самый вес, что и обратная - от второй к первой. Такое различие в весах может указывать на то, что одна тема является подтемой другой.
Семантическая сеть представляет собой тематический индекс анализируемых текстов, который используется для поиска документов по теме, а также для расширения запроса ассоциативно связанными темами. По каждой из тем сети формируется набор связных фрагментов текста – цитат, относящихся к соответствующей теме, которые представляют тематическое резюме (реферат) текста. Кроме того, выполняется ранжирование этих фрагментов по весам (от 0 до 100), которые отражают их информативность для соответствующей темы. Общее резюме текста формируется из наиболее информативных фрагментов по ключевым темам документа. При разбиении текста на связанные по смыслу фрагменты используется лингвистический алгоритм выявления групп предложений, связанных общностью содержания – сверхфразовых единств. Кроме того, учитывается формальная разметка текста документа (например, для HTML-документов).
При анализе текста можно воспользоваться семантической сетью, построенной на базе других текстов (эталонных). Например, если по текстам определенной предметной области построена семантическая сеть, ее можно использовать для фильтрации информации из других текстов. В этом случае в текстах выявляются только те темы, которые содержатся в эталонной сети, и резюме строятся только по этим темам.
Сравнение семантических сетей различных текстов позволяет установить степень их смысловой близости, что может использоваться для автоматической классификации документов по заданным рубрикам, поиска документов по подобию заданному тексту, а также кластеризации информационного массива на классы документов близкого содержания.
Возможности
Технологии автоматического анализа содержания текста предназначены для решения следующих задач:
Тематический анализ текста документа
Позволяет получить список ключевых тем текста, которые представляются как отдельными словами, так и устойчивыми сочетаниями слов.
Использование средств тематического анализа дает следующие возможности:
● проводить поиск документов по интересующей теме, что увеличивает точность и полноту по сравнению с простым контекстным поиском;
● визуализировать список ключевых тем в ходе просмотра документов для быстрого ознакомления с их содержанием, что ускоряет выбор требуемой информации;
● исследовать тематический состав и вести мониторинг информационных потоков.
Выявление смысловых связей в тексте
Выявляет смысловые (ассоциативные) связи между ключевыми темами текстов. В комплексе с тематическим анализом устанавливает для каждой темы ряд близких тем, ассоциативно связанных с ней в тексте документов. В результате формируется «смысловой портрет текста» в форме ассоциативной семантической сети.
Определение связей между темами полезно, прежде всего, для аналитических целей и позволяет:
● исследовать семантическое окружение тем в коллекции документов;
● расширять или уточнять запросы при поиске близкими темами;
● выявлять последовательность смысловых переходов, связывающие заданные темы.
Автоматическое реферирование текста документа
Средства автоматического реферирования позволяют разбить текст на множество семантически целостных фрагментов, отражающих основные темы документа, и выделить наиболее информативные.
Функция реферирования может использоваться для:
● построения тематических рефератов по темам документа;
● построения общего реферата по ключевым темам;
● построения рефератов по теме, заданной эталонными текстами.
Автоматическая классификация документов
Средства автоматической классификации позволяют:
● классифицировать документы по темам, заданным эталонными текстами;
● классифицировать документы по темам, автоматически выделенным в коллекции документов;
● кластеризовать информационный массив, выделяя тематические классы близких по содержанию документов.
Источник: Компания Гарант-Парк-Интернет (research.metric.ru)
Похожие статьи

ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 2
Обратим внимание на полную цитату.
Автор пишет "...иногда пользователь не знает точно, какую именно информацию ему хотелось бы получить, имея лишь общее представление о границах своих интересов...".
Переформулируем.
Вторичная потребность пользователя в информации может быть не осознанна вполне, но первичная потребность - получить удовлетворение (через получение недостающих голове знаний) - толкает пользователя на поиски.
Таким образом, не все равно, какую информацию пользователь получит "на выходе": он должен получить удовлетворяющую информацию вне зависимости от ее конкретики.