
Разбираем интеллектуальный ввод документов на примере работы с входящими договорами

Разбираем интеллектуальный ввод документов на примере работы с входящими договорами
Тема автоматического извлечения структурированных данных из текстовых документов не является новой, но и закрытой её назвать нельзя. В контексте СЭД существует ряд сценариев, где применение данного подхода выглядит весьма перспективно, один из них – это работа с входящими договорными документами. Предлагаю углубиться в этот сценарий, и на его примере выяснить, с каким подводными камнями можно столкнуться при попытке автоматизировать процесс извлечения структурированных данных из текста.
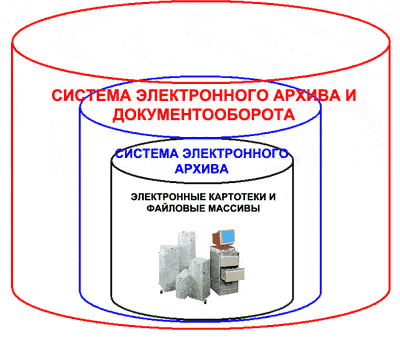
ЗАХВАТ ДОКУМЕНТА
Первое, на что стоит обратить внимание, это то каким образом договор попадает в систему. Чем меньше действий потребуется для занесения документа в СЭД, тем лучше. Вот список того, что приходит на ум:
- Договор хранится на внешнем накопителе, пользователь создаёт электронный документ через интерфейс СЭД на основе файла.
- Договор приходит вложением в электронное письмо, в почтовом клиенте через меню интеграции пользователь отправляет документ в систему.
- Договор приходит ссылкой на облачное хранилище (Dropbox, Google Диск и т.п.) по электронной почте, интеграция почтового клиента с системой определяет наличие в тексте письма ссылки на документ и предлагает пользователю занести его в СЭД.
- Договор уже открыт в приложении редакторе (MS Word, OpenOffice), через меню интеграции пользователь отправляет документ в систему
Выше представлены варианты, при которых пользователь лично инициирует процесс создания договора в системе, но не стоит забывать и о потоковом вводе, когда документы заносятся в систему в молчаливом режиме.
СИНТАКСИЧЕСКИЙ АНАЛИЗ ДОКУМЕНТА
Это самый интересный шаг, именно здесь происходит вся магия превращения текста в набор структурированных данных. При имплементации алгоритма синтаксического анализа документа стоит обратить внимание на следующее:
- Полезными данными, которые можно извлечь из договора, являются: номер договора, предмет договора, дата составления, место составления (город), реквизиты сторон (юридическое наименование, юридический адрес, фактический адрес, ИНН, КПП, расчетный счет, корреспондентский счет, БИК, ОКПО, ОГРН, ОКВЭД, ФИО ответственных), наличие приложений и информация по ним.
- Есть два подхода к анализу документа: рассматривать только текст или текст + контейнер. Первый вариант дешевле и быстрее, второй дороже и эффективнее. Документы MS Office (.docx) являются zip-архивами содержащими Office Open XML разметку, по сути документы уже структурированы и содержат информацию о параграфах, страницах, колонтитулах, шрифтах и т.п., что несомненно может быть полезно при разработке алгоритма. Почему? Во-первых, это поможет предварительно разбить договор на разделы, отделив основную часть от приложений. Во-вторых, появится информация о физическом местоположении текста на странице (конец, начало, колонтитул). В-третьих, появится доступ к графической информации, это могут быть подписи или штрих-коды. В-четвертых, возможность корректно обрабатывать текст находящийся в таблицах и прочих визуальных элементах. В-пятых, информация о том, является ли текст выделенным, подчеркнутым и т.п.
- В РФ существует 9 видов договоров, однако способов их оформления бесчисленное множество. Интересующие нас данные могут находиться в самых неожиданных местах документа. В ходе исследования выяснилось, что часть договоров поддается шаблонизации, однако всегда присутствует вероятность получить на вход договор, оформленный человеком с весьма изощрённой фантазией. Мне видится привлекательной возможность добавления элементов машинного обучения, это позволит алгоритму саморазвиваться, обучаться на новых документах, при этом необходимо обеспечить качественную первоначальную обучающую выборку.
- Для корректного извлечения данных необходимо разбивать документ на смысловые блоки. Договор, как правило должен содержать блок реквизитов своей организации, блок реквизитов контрагента(ов), заголовочный блок с информацией о номере, дате, местоположении. При этом, блоки реквизитов с большой долей вероятности будут находиться в конце основной части договора, перед приложением. Выделение таких закономерностей позволит уменьшить количество ошибок синтаксического алгоритма.
ПОЛЬЗОВАТЕЛЬСКИЙ КОНТРОЛЬ
Задача этого этапа - позволить пользователю проверить корректность работы алгоритма извлечения. Реализация может выглядеть следующим образом:
- Вызов диалоговых окон непосредственно в процессе извлечения данных, для подтверждения корректности извлекаемых данных и разрешения возможных конфликтов. Этот подход обеспечивает наибольшую гибкость, но требует активного участия пользователя.
- Отображение карточки созданного документа с извлеченными метаданными в интерфейсе СЭД, от пользователя требуется только сохранить изменения.
- Ведение журнала по всем обработанными договорам, с фиксацией всех конфликтов и результатов. От пользователя (администратора) требуется разрешить возникшие конфликты и сохранить результаты. Этот вариант оптимален при потоковом занесение документов.
Представленные принципы применимы для решения и других задач. Например, автоматическое извлечение данных о кандидате из резюме - упростит работу HR-отделов, а анализ входящей корреспонденции поможет в актуализации данных о внешних контактах и организациях. Стоит отметить, что перечь возможных сценариев можно существенно расширить, если ко всему добавить инструмент семантического и морфологического анализа текста, который позволит учитывать смысловые связи между словами, синонимы и многое другое.
Похожие статьи

ваш личный спасательный круг
в цифровизации бизнеса
с полезными советами и новостями
от экспертов
Присоединяйтесь, будем на связи!
Комментарии 9
Не ставя под сомнение интересность вопроса по осмысленному анализу документа, хочу поинтересоваться - а на сколько обоснованной выглядит задача такого анализа?
Поясню - когда мы говорим о распознавании большого текстового документа или, например, счета-фактуры, мы понимаем, что ручная оцифровка этих документов занимает достаточно продолжительное время, многократно превосходящее время на проверку результата (особенно если интерфейс для проверки хорошо продуман).
А когда речь идет о 5-6 полях... Не проще ли заполнить их вручную благо речь ведь не идет о наборе вручную, а лишь о копировании?
Т.е., условно говоря, добавьте в интерфейс того же MS Word боковую панель с обязательными реквизитами документа (можно и с автоматической валидацией для тех полей, для которых она возможна) и пусть оператор таскает нужные данные из текста на эту панель.
Ну а вариантов развития/упрощения тут море - добавление действий по копированию в контекстное меню (например, выделил число, открыл контекстное меню, а там "Занести как БИК заказчика" или "Занести как БИК исполнителя", т.к. по формату число ничто иное как БИК).
Т.е. мой исходный вопрос можно переформулировать так: а не будет ли более выигрышным в данной ситуации сделать ставку на серьезное упрощение интерфейса оператора, нежели разрабатывать систему интеллектуального анализа, да еще и снабжать её интерфейсом контроля?
Михаил, люди масштабируются хуже, чем компьютеры.
Не понял, при чем тут масштабирование?
Артём же черным по белому написал: последний этап - ручная верификация. У меня лично перед глазами есть несколько примеров того, когда исправление 10% (условно) ошибок автоматического распознавания стоили дороже, чем изначально полностью ручная оцифровка. Речь не о текстах.
Придется добавлять панели и в Excel, и в Adobe Reader. Хотя способ удобен, но даже в нем хочется сделать следующий шаг: пусть хотя бы часть полей сразу попадет в нужные поля ввода. Ведь очевидно, что номер договора -- вот он, что заказчика надо взять отсюда.
Люди всегда хотят большего, и если есть возможность -- надо попробовать им это дать.
Роман, давайте по порядку.
Будем рассматривать вопрос относительно всё той же задачи со входящими договорами. Форматы и способы оформления договоров крайней разнообразны и их объем может сильно варьироваться, от 2 страниц до 50 и более, при этом места где находятся эти самые 5-6 полей могут из раза в раз отличаться (да и последовательность то же), что потребует от пользователя существенных усилий для поиска и копирования каждого поля через ctrl+c/v.
Зависит от того, как видеть конечную цель. Естественно, можно не усложнять задачу и попробовать оптимизировать процесс не меняя его сути, ограничиться интеграцией с приложением редактором (о чем я пишу в разделе захват документа). Но если говорить о тиражируемом продукте, то комплексное решение с распознаванием может стать интересной фичей, которая заинтересует потенциального клиента. Особенно, если клиент - крупная компания, через которую проходит круглое количество договоров ежедневно и такой интеллектуальный подход позволил бы существенно упростить жизнь операторов, а то и вовсе заменить их всех одним сотрудником следящим за процессом.
Ручная верификация это один из вариантов, я так же писал и о потоковом вводе в молчаливом режиме, при котором ведется журнал, который должен периодически проверять администратор, при этом журнал может содержать информацию о точности распознавания и об ошибках, что уменьшит объем ручной работы. Если учитывать возможность применения алгоритмов машинного обучения, то со временем решение будет подстраиваться под те форматы договоров, с которыми имеет дело организация и количество ошибок может сойти на 0.
Риски есть всегда и везде, нужно адекватно взвесить возможности и понять, получится ли разработать решение, профит от использования которого превысит цену возможной ошибки.
Давайте. Начнем с того, что Михаил.
Не спорю, но не вы ли в самой статье написали, что
Так что вы уж определите для себя - документы уникальны или преобладают общие подходы к заполнению.
Предположительно. А может и не потребует. Я привел только несколько самых очевидных вариантов улучшения интерфейса. А их может быть бесконечно много.
Ну я бы тогда предложил посмотреть еще дальше и от казаться от хранения типовых документов (типа договоров) в виде неструктурированного текста. А обычный Word это (я не согласен с утверждением статьи) - неструктурированный документ. Структурированным он станет если начать заполнять поля в документе. Т.е. работать с ним как с электронной формой.
И вообще, что это за компания у которой идет огромный поток входящих договоров с абсолютно разными контрагентами?
Это звучит, конечно, здорово, только вот большинство заказчиков использует СЭД для уменьшения рисков, а вы говорите о внесении дополнительных.
И вообще, на какой объем входящих договоров в день вы ориентируетесь? 10, 100, 1000? Сколько занимает оформление одного договора вручную? У всех ли из них ВСЯ необходимая для оформления информация содержится в теле документа?
Так и анализ придется делать для каждого, и верификатор, наверняка, тоже.
Откровенно говоря, не очень.
И ещё всё никак не могу понять - заполнение реквизитов это от 1 до 5 минут (при совсем нетиповом договоре или коряв введенных реквизитах. Но тут и автораспознавание сломается). Вычитка и правка - часы. Стоит ли овчинка выделки?
Прошу прощения, Михаил, я не нарочно :)
По поводу верификатора, его можно вынести в отдельный блок (интерфейс) и не встраивать во все приложения редакторы, в случае с потоковым вводом сделать это можно прямо в интерфейсе СЭД.
Существуют закономерности, которые будут справедливы для большинства документов, возможно и ветвление с несколькими различными ситуациями, которые можно учесть в алгоритме. Не нашли по одним признакам - не беда, пробуем найти по другим. Все таки ручной поиск займёт значительно больше времени, даже если известно что требуемая информация "где-то там".
И всё же, я думаю, что без применения хотя бы минимального анализа текста документа (его структуры), это вряд ли уйдёт дальше по эффективности чем пресловутый ctrl+c/ctrl+v.
Речь идёт о решении, которое должно одинаково хорошо работать с различными форматами договоров в различных организациях без необходимости вносить доработки. Я согласен, не факт что форматы будут существенно различаться в рамках одной компании, хотя мне кажется такие ситуации тоже возможны.
Эти вопросы стоит обсудить в рамках отдельного поста, там есть где развернуться в плане статистических выкладок :)
Смотря как делать. Если вам придется отрисовывать каждый документ чтобы показать контекст обнаружения поля, то придется делать рендер (или встраивать готовый) для каждого из имеющихся форматов.
Попробовать можно. Только нужно не забыть, что:
Поэтому, поставь передо мною задачу ускорения ввода документов а-ля договоры, я бы пошел поэтапно:
Но вот все равно не могу представить компанию, где был бы потоковый ввод договоров причем это не договоры по её же шаблону (например, клиентские договоры) - а здесь точно нужно не распознавание, а генерация документа.